Overview: The anterior cerebral artery is a unique vessel, in many respects. Phylogenetically, it is among the oldest vessels in the telencephalic species. Embryologically, its early connection with choroidal vasculature and primary role as a rostral internal carotid artery trunk, lead to many important variations with substantial clinical significance — cerebral aneurysm and perforator AVM supply are some examples. The following, somewhat outdated presentation on the ACA will be modified as time allows
Embryology and phylogeny
The best place to see this is on the dedicated vascular neuroembryology page. For the abbreviated version — as soon as beast had a telencephalon, way before the PCA and MCA, it had its own ACA. The oldest part of the cerebral cortex is the olfactory lobe — all three layers of it, up in the front of head, and fed by the ACA homolog. The early ICA consists of two trunks — rostal and caudal. Rostral is ACA, caudal is PCOM and posterior fossa vessels, not PCA. With continued evolution, the ACA supports olfactory lobe, and its perforators supply parts of what becomes basal ganglia. The MCA, in fact, arises as a dominant cortical vessel from a group of ACA perforators (see embryology page, again), which explains some of its variants (accessory MCA types). In the human, the ACOM forms relatively early in a plexiform way, which leads to its many adult variations. Phylogenetically, all kinds of solutions to the ACOM region are seen as “norm” in a given species — from no ACOM to the “azygous” configuration, the same patterns are seen in the human, whose classic ACOM is but one of many possible arrangements. Some variations of the ACA relate to its early supply to the orbit via the ventral ophthalmic artery (see example below) — for example, the infraoptic course of the ACA is persistence of the ventral ophthalmic in setting of “true” A1 hypoplasia.
It used to be, that the most common search string leading to this website “hit” was the “Azygous ACA” or some variant of anterior cerebral artery. I am not sure why that was, since there is very little on this site on the subject, and I must say (since I have nothing to sell you) that the subject is not all that exciting for me. I can’t help saying at the outset that the debate on ACA nomenclature is very silly. It’s really quite simple: there are usually two anterior cerebral arteries, with right and left A1 and A2 segments. Sometimes, however, there is only one A2 segment, with no ACOM. Call it what you like; I prefer to say that the “A2 segment is unpaired to the level of…” and leave it at that. Call it Azygous if you like (the Lasjaunias and Berenstein definition of an Azygous ACA is one that is unpared for its entire length — from A1 confluence to the very end, supplying both hemispheres with individual branches arising from a common trunk), but it will invariably confuse some people who have a different notion of what Azygous ACA is.
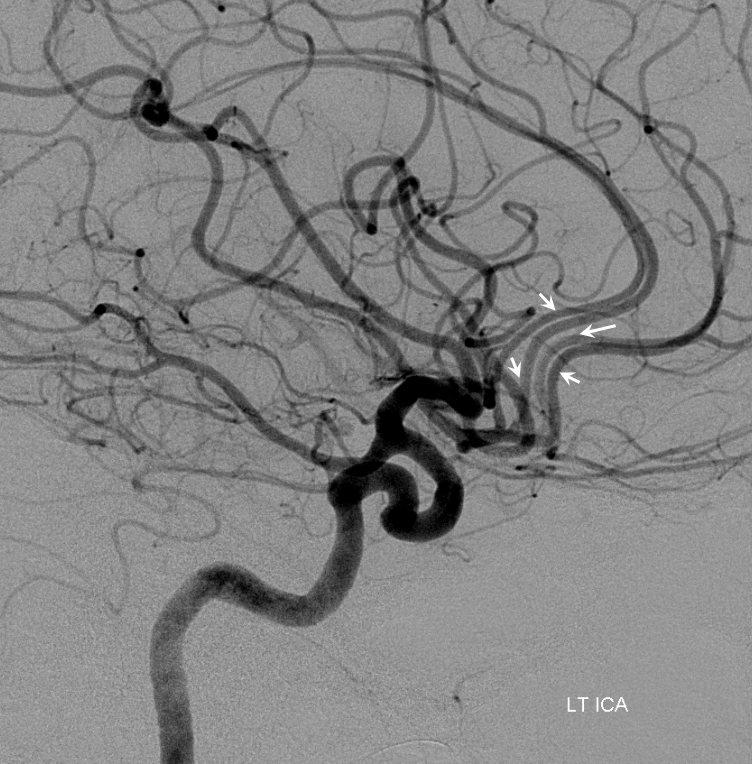
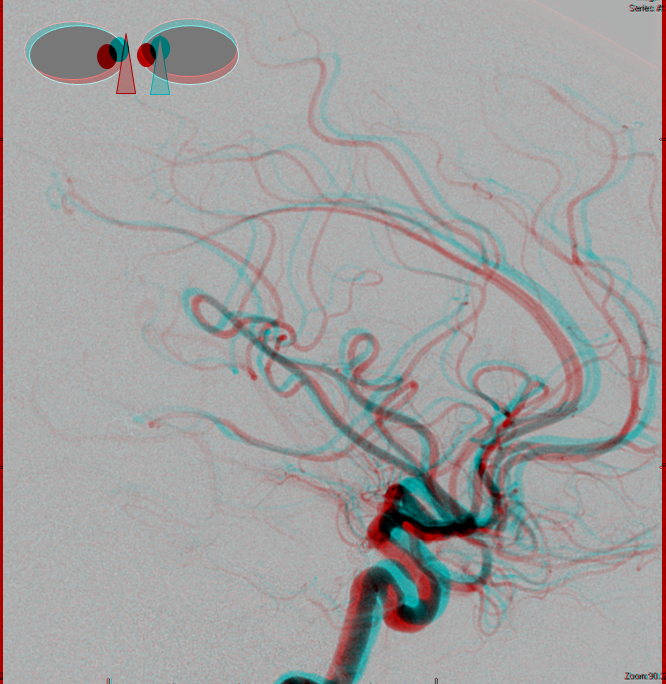
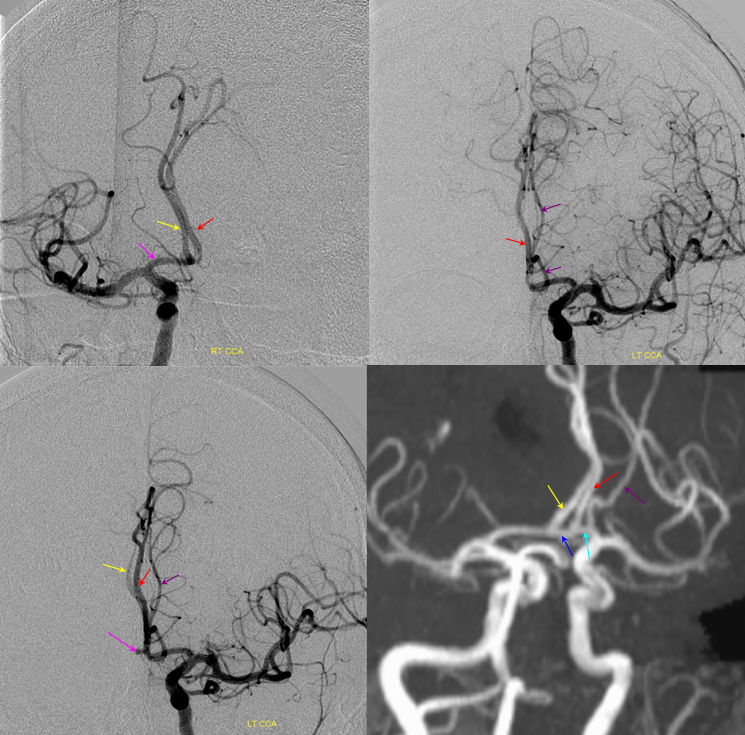
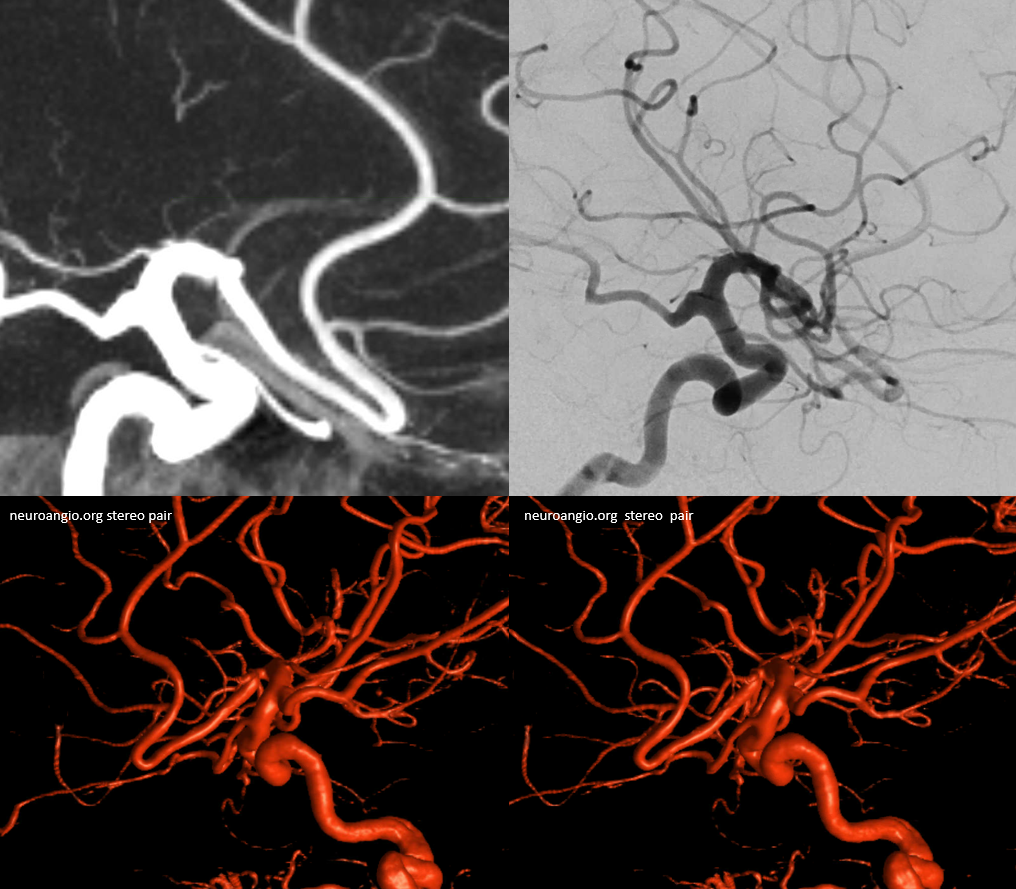
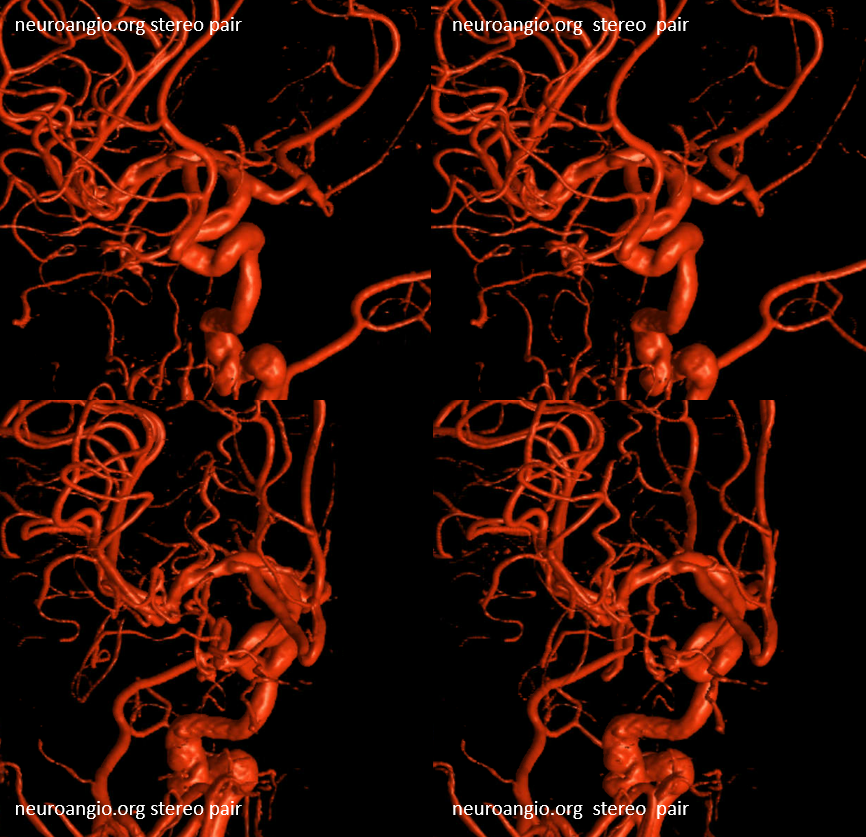
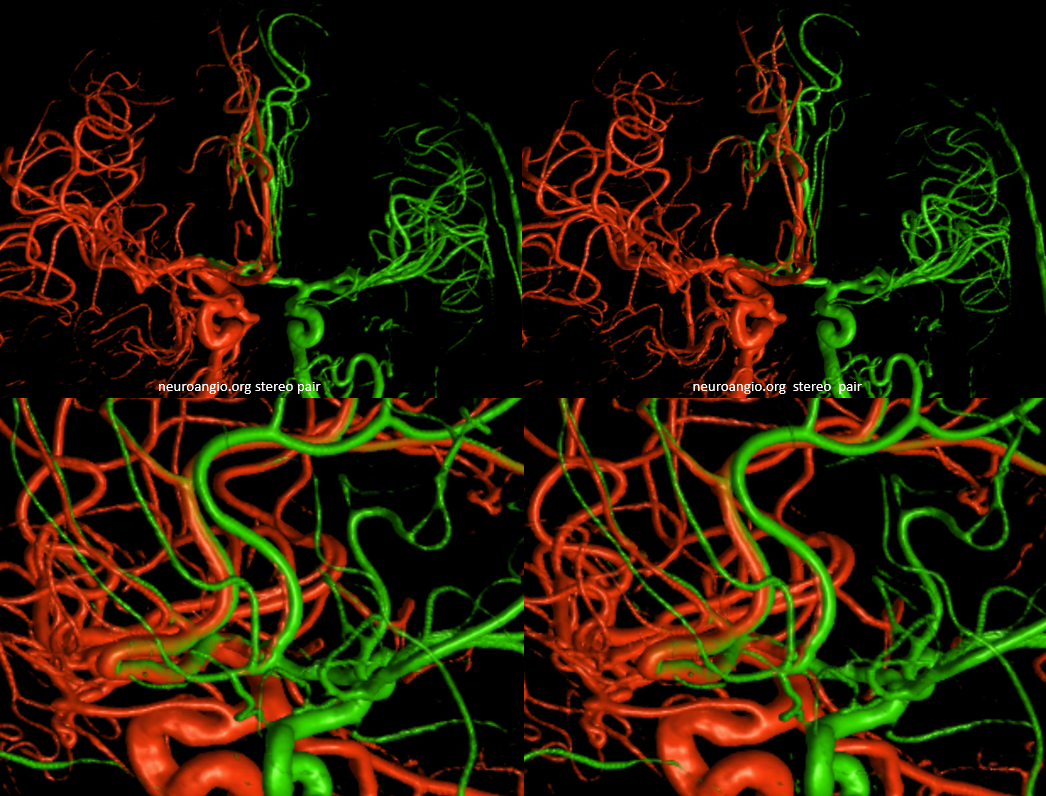
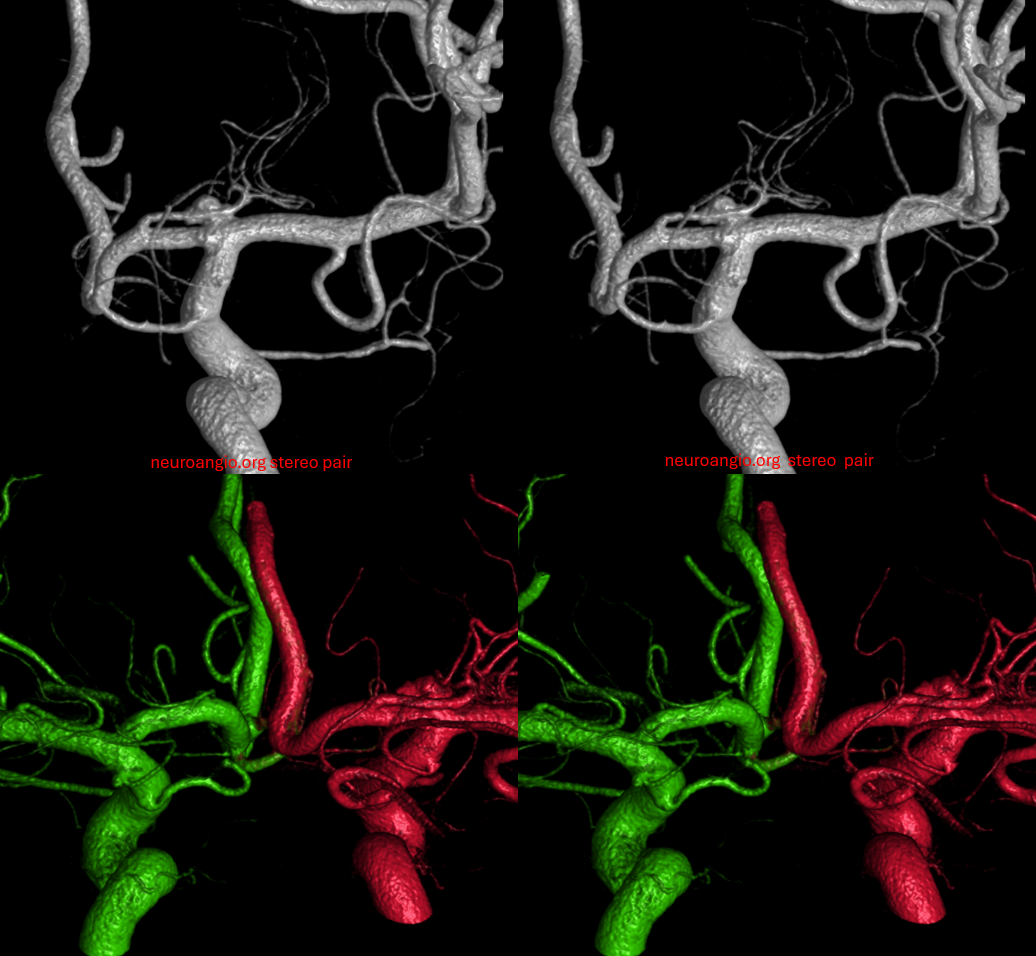
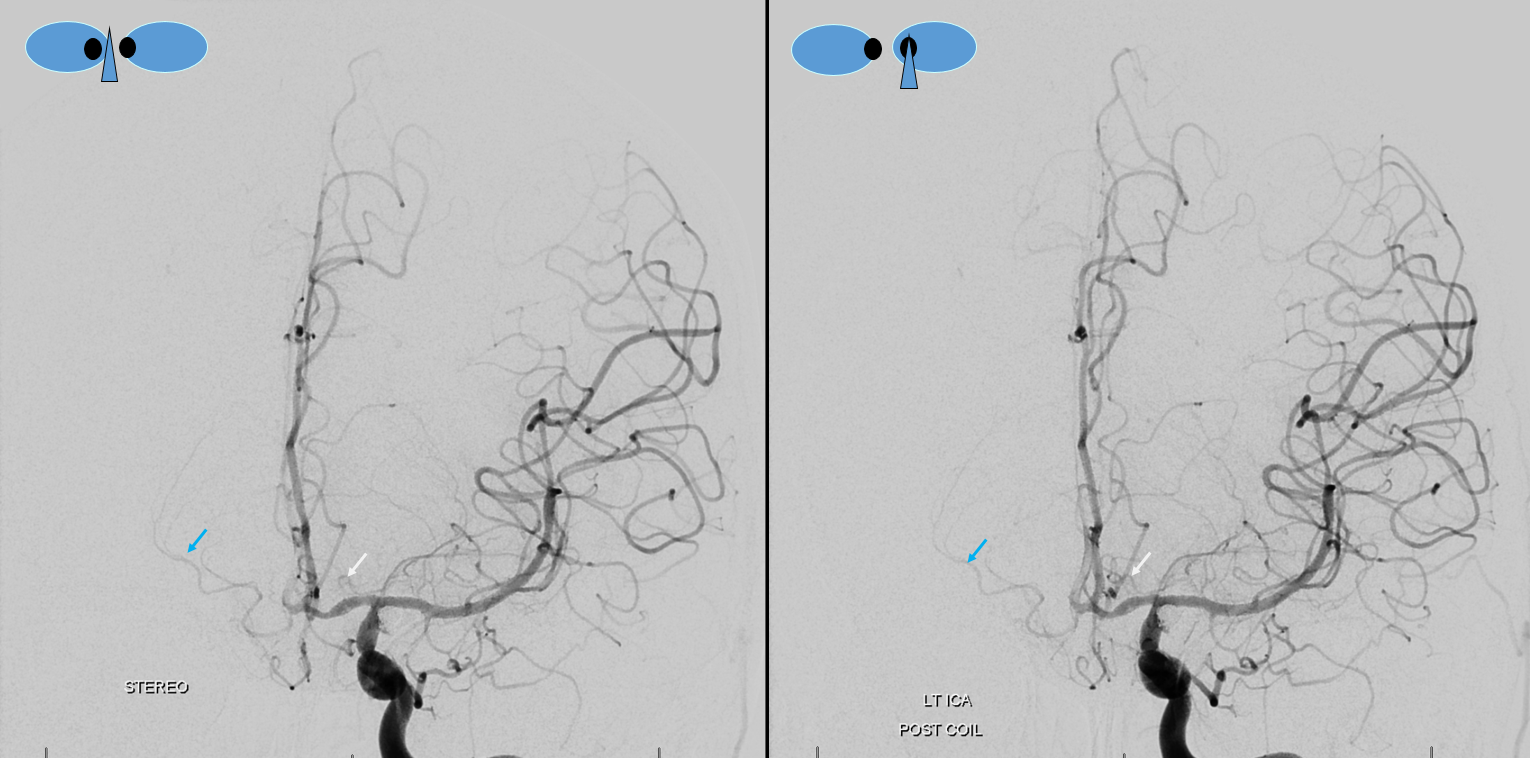
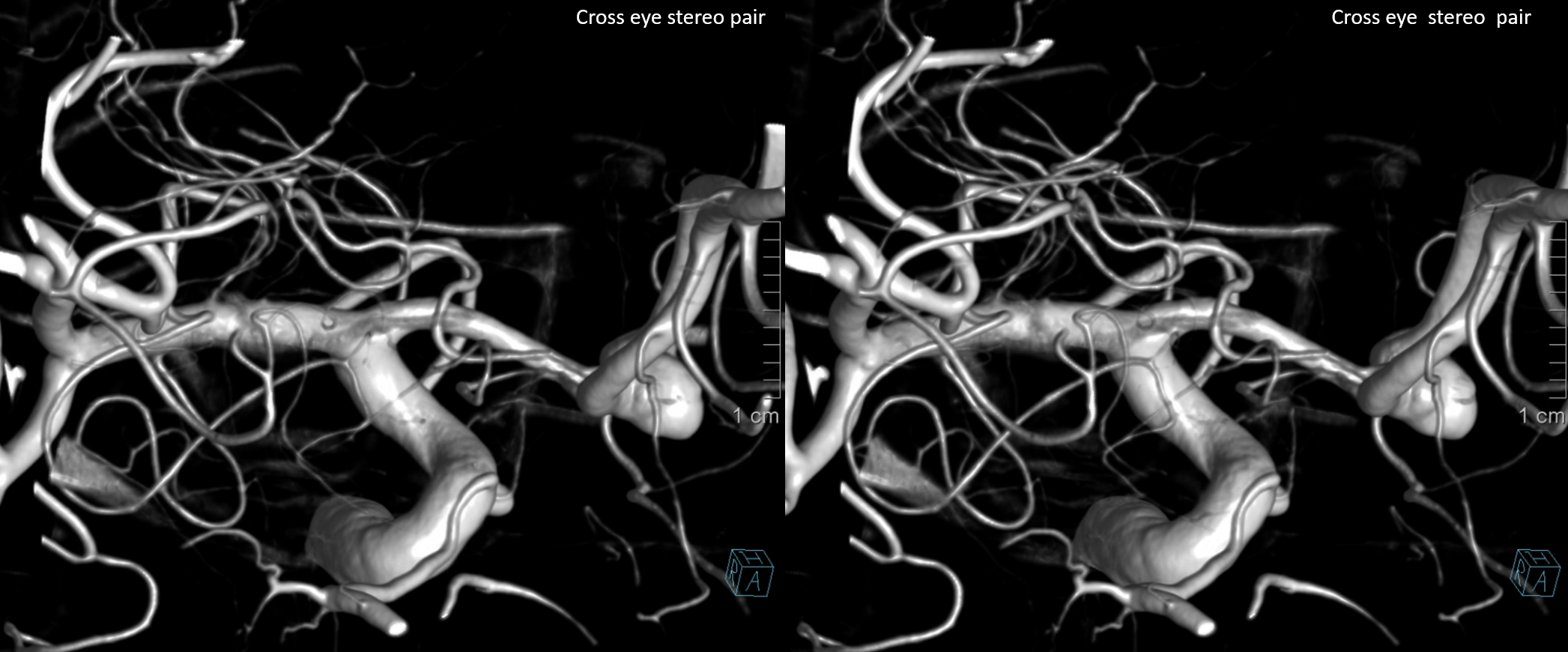
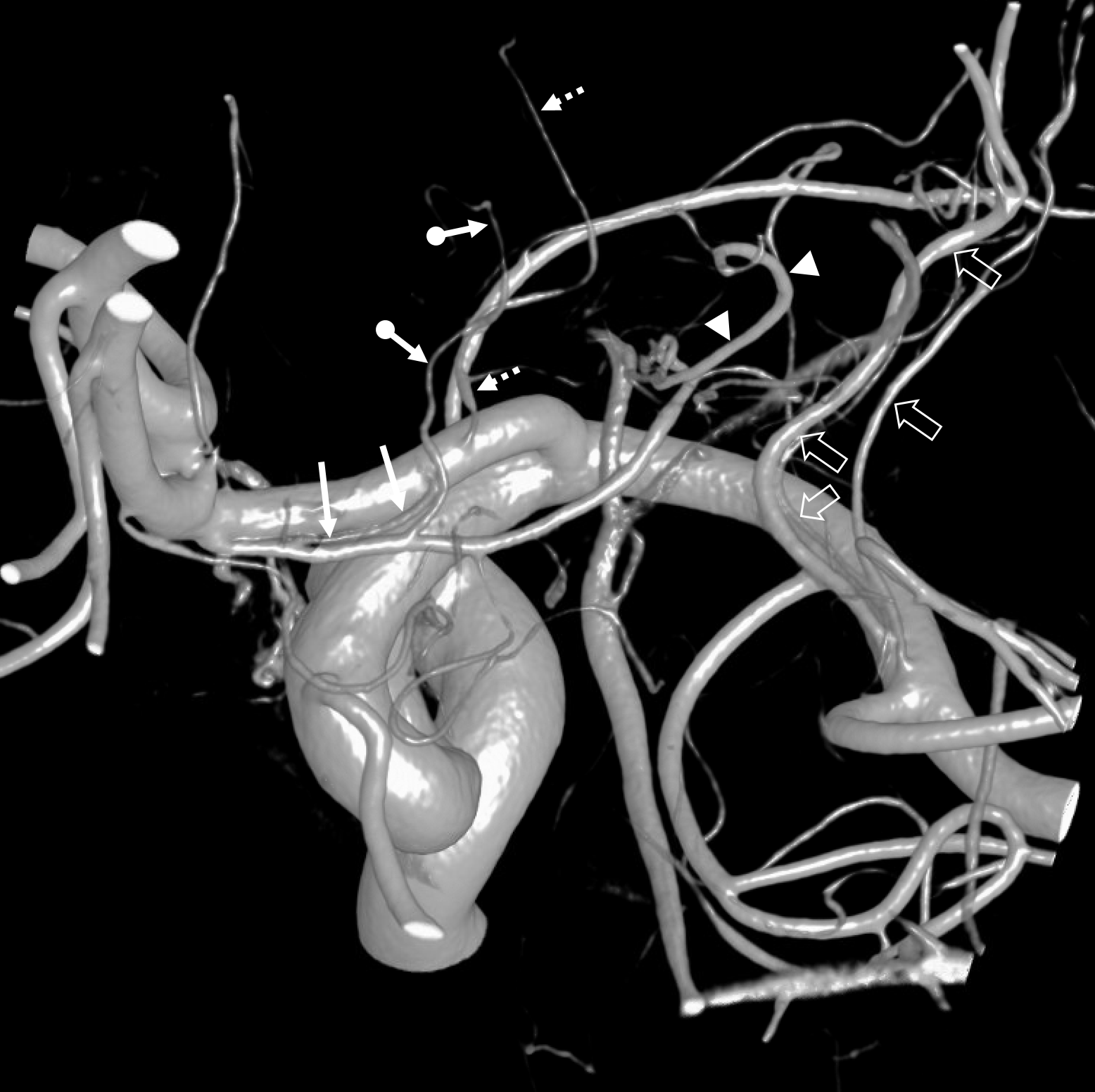
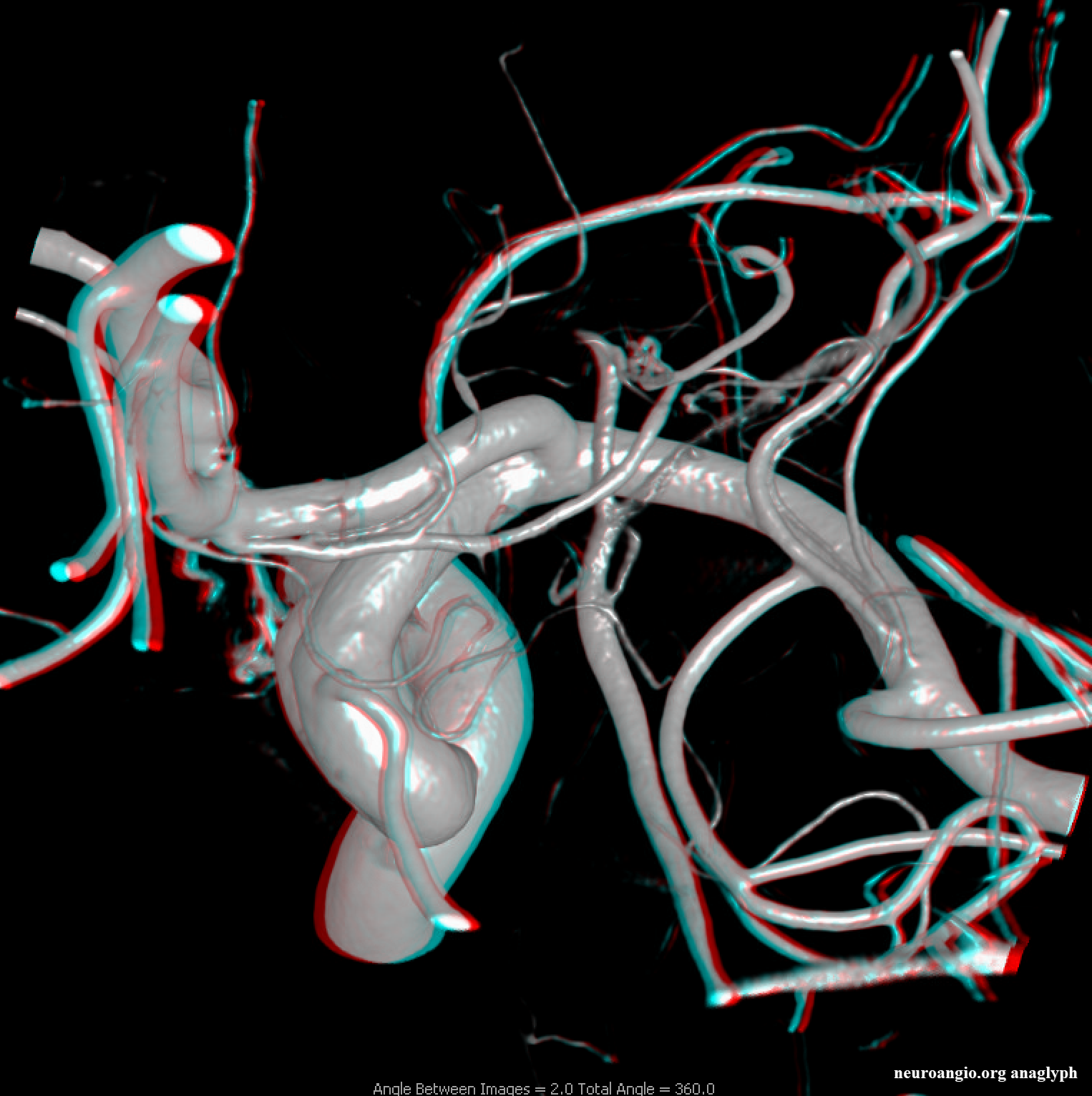
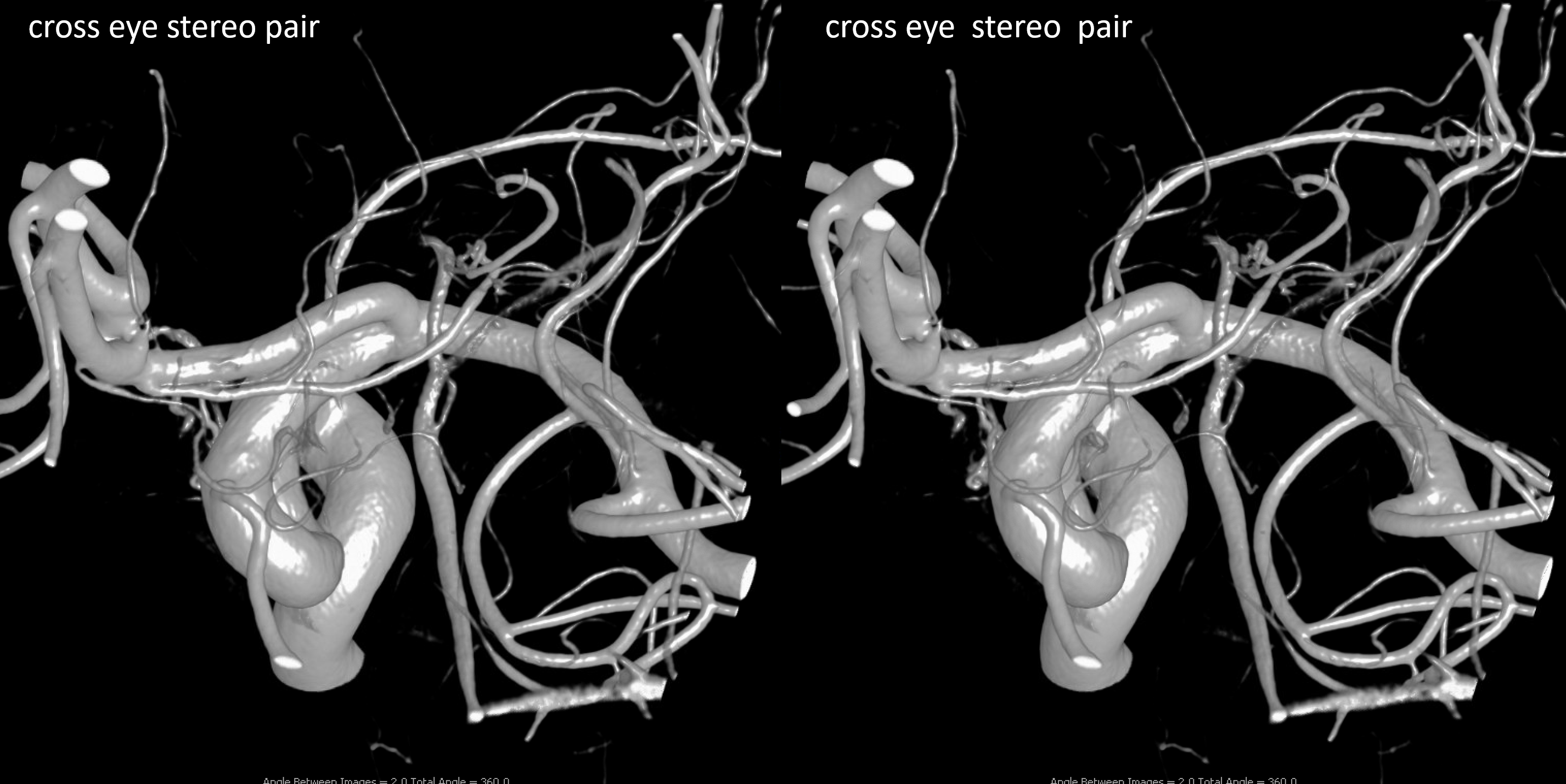
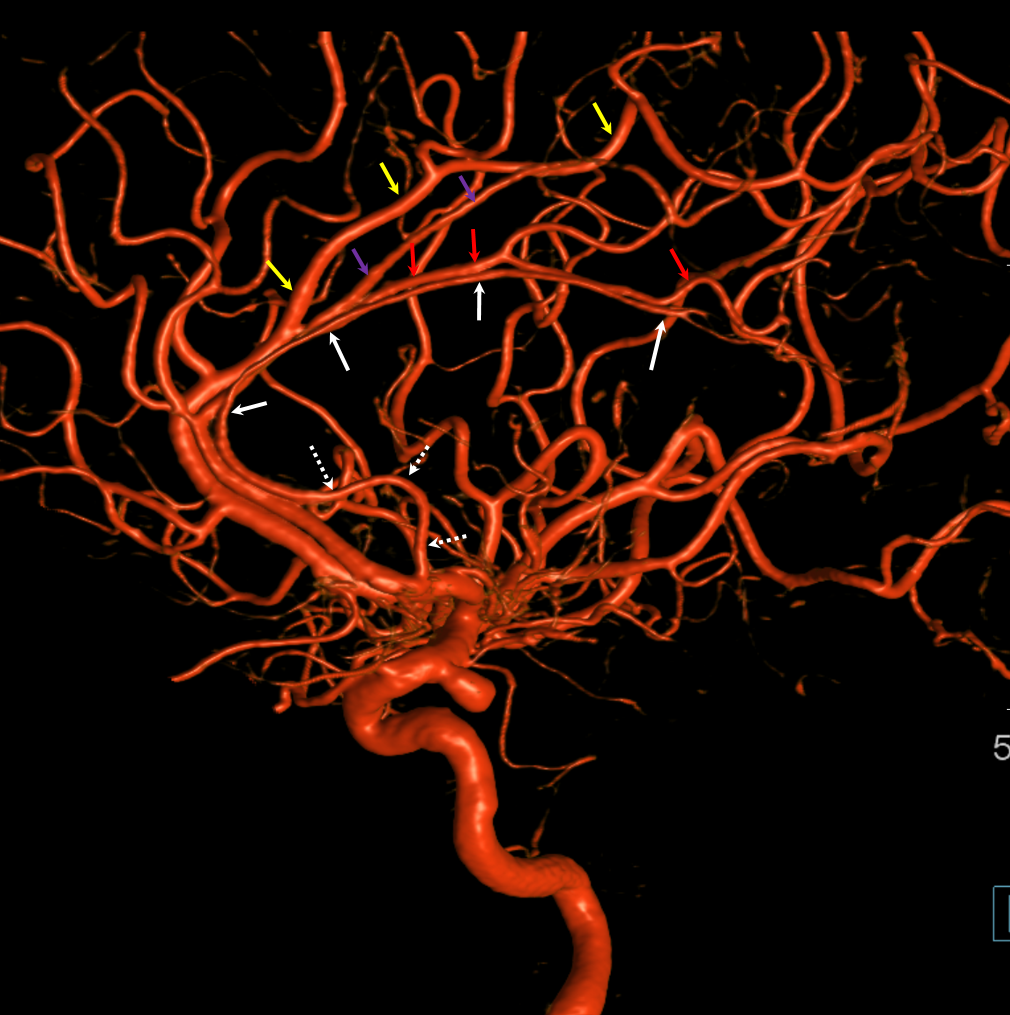
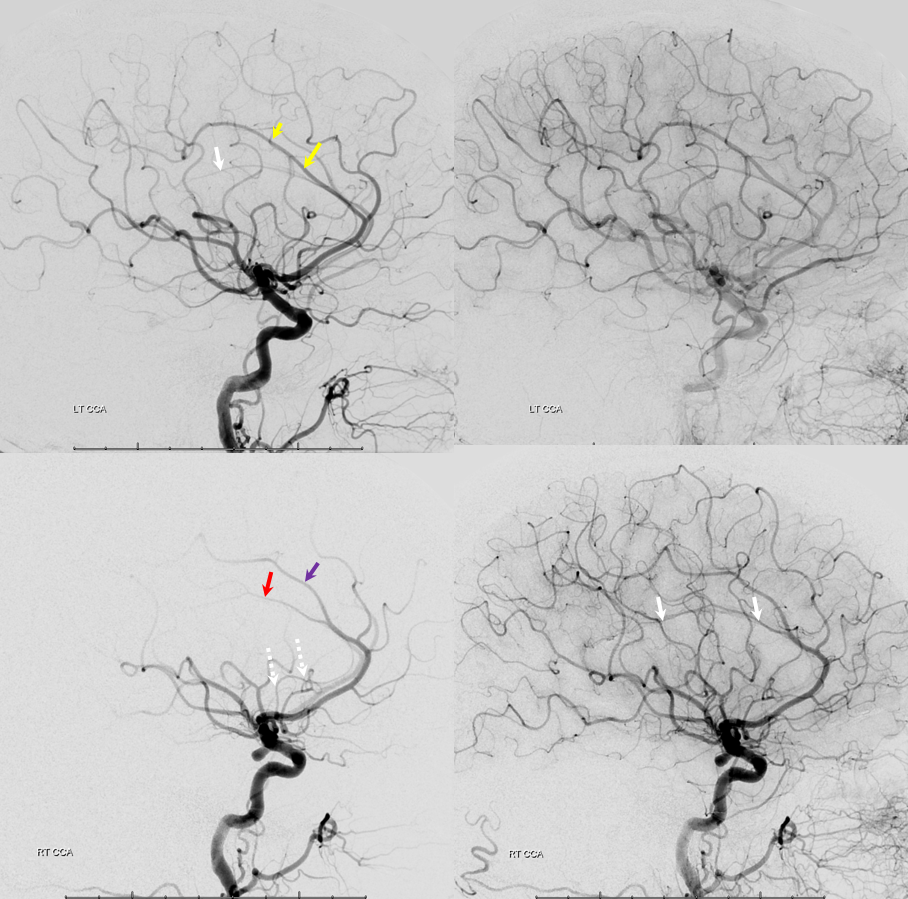
Other silly nomenclature concerns the bifurcation pattern of the ACA. For example, the idea of “triplicated” or “quadruplicated” anterior cerebral arteries — depending on how many vessels emerge from the ACOM complex -2, 3, or 4 — is total nonsense. The right way to look at it is quite simple — the ACA generally has pericallosal and callosomarginal divisions. Classically, an A2 segment bifurcates into these pericallosal and callosomarginal divisions (with all manner of variations, for example dominant pericallosal or dominant callosomarginal trunks). The length of the A2 segment is variable however — sometimes it is very short or almost nonexistent, so that the pericallosal and callosomarginal trunks arise separately from the ACOM region or just distal to the ACOM. When this happens, it appears as though there are two “anterior cerebral” arteries arising from the ACOM — this is simply an early pericalossal-calossomarginal division. If this happens bilaterally, it may look like an ACA “quadrifurcation”. That’s all there is to it. Here is an example of such bilateral early bifurcations on angiography, with 4 branches (2 pericallosal, and 2 callosomarginal) arising from the ACOM region. The more anterior ones are callosomarginal, and the more posterior two are pericallosal, as always.
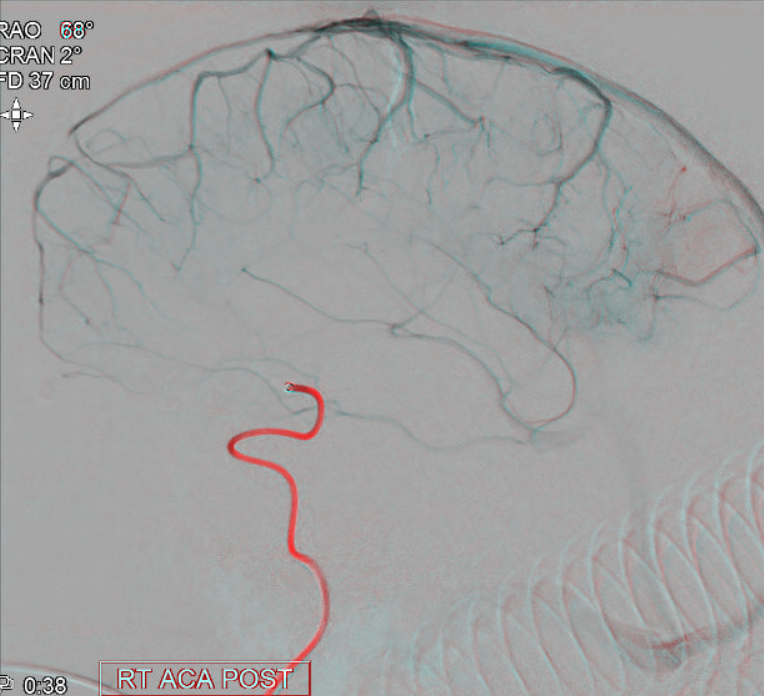
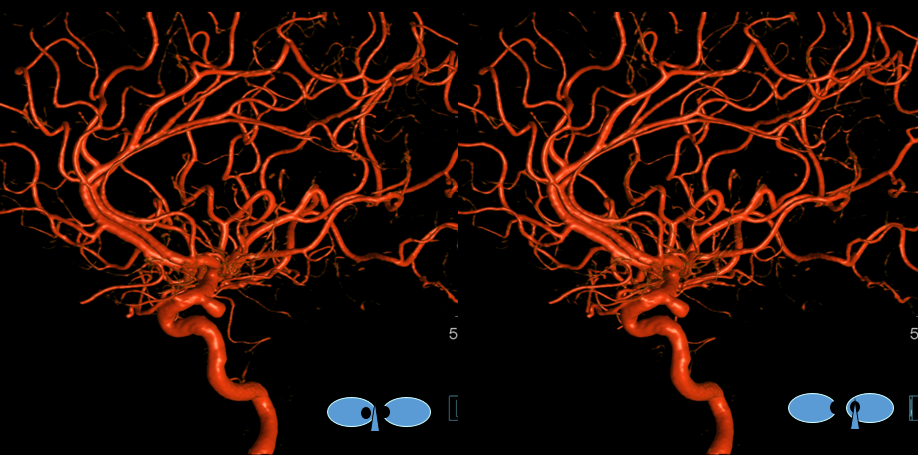
Same patient, stereo pair. The pericallosal division is dominant and supplies the primary motor and sensory areas. The callosomarginal is limited to mesial anterior and mid-frontal regions.
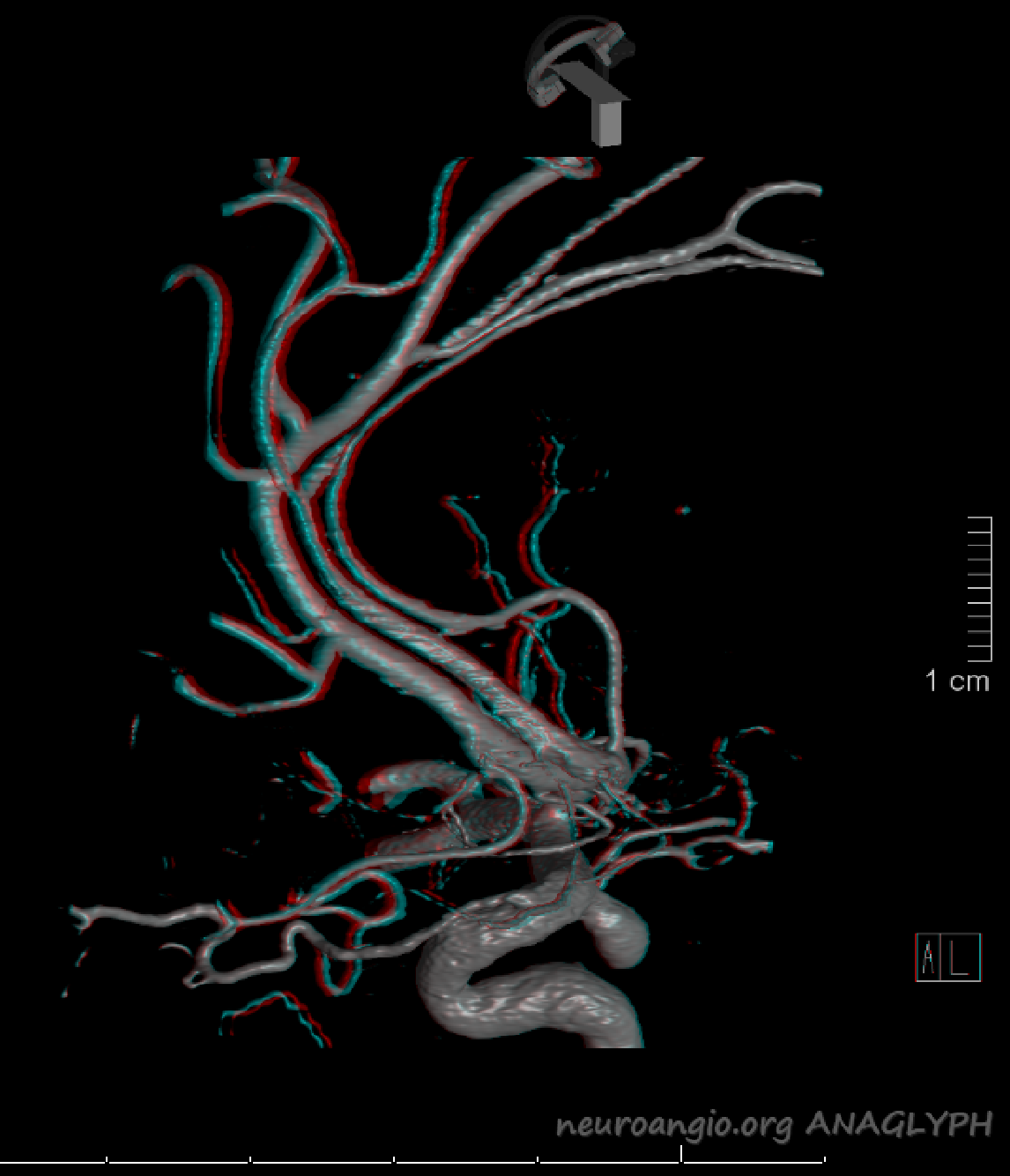
Anaglyph
The same goes for the “triplicated ACA” — there is really no such thing. It only looks triplicated — the third branch is either a frontopolar or an early division into pericallosal and callosomarginal branches immediately near the ACOM, or a Heubner with hypoplastic A1, etc. These types of nomenclature are bound to generate more problems than they were well-meaningly meant to solve. Enough of this however — to the pictures…
Duplicated A1 segment — this is not an uncommon incidental finding. It has a very low increased association with presence of berry aneurysms. On very rare occasion, the optic nerve can go through the fenestration, which implies a very different embryologic pattern from the more common supraoptic fenestration. The fenestration must obviously be kept in mind if surgical dissection is contemplated.
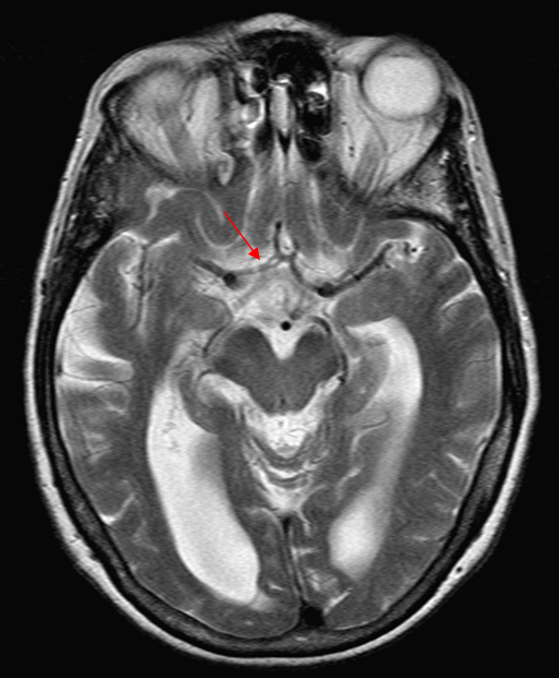
Another patient with a fenestrated A1, stereo pair from CT angiogram
Anaglyph
Unpaired (Azygous) Anterior Cerebral Artery
A single ACA A2 segment distal to the A1 confluence that never bifurcates again is sometimes called an Azygous ACA, but I think it adds more clarity and simplicity to call it unpaired to the level of whatever (pericallosal, callosum genu, etc). There is no ACOM, by definition. The incidence is about ~0.1-1%, depending on the author. Embryologically, its significance is unclear. Phylogenetically, it is the “normal” disposition in some monkeys and other mammals. There is a resemblance to the vertebrobasilar arrangement, but it may just be a resemblance only. You may think of it as an ACOM gone berserk, but that’s probably wrong also. This disposition carries a strong association with aneurysm formation at the terminal end of the unpaired segment, or at the calossomarginal takeoff region, as illustrated below.
Images of the aneurysm courtesy of Dr. J.A. Bello and Dr. A. Brook, Montefiore Medical Center, The Bronx, NY — this is the first brain vessel variant i’ve ever come across in medical school. Its not a good thing to have. Here is a case of azygous ACA embolus (with delayed diagnosis due to bilateral lower extremity weakness) and thrombectomy. I hope never to see one again.
Confusion can arise when this unpaired A2 segment is associated with early takeoff of the frontopolar branch of the ACA or a hypertrophied Heubner. This branch originates from the A1 segment proximal to A1 fusion into the unpaired A2 segment. The resulting appearance makes it seem as though there is an ACOM — in fact it is NOT an ACOM but A1 segment distal to the frontopolar origin but proximal to the contralateral A1 fusion. Recognition of the correct anatomy is very important for surgical planning.
Occlusion of Azygous ACA
The most pronounced symptom is bilateral lower extremity weakness, which can mimic a spinal syndrome. A case of this is shown here
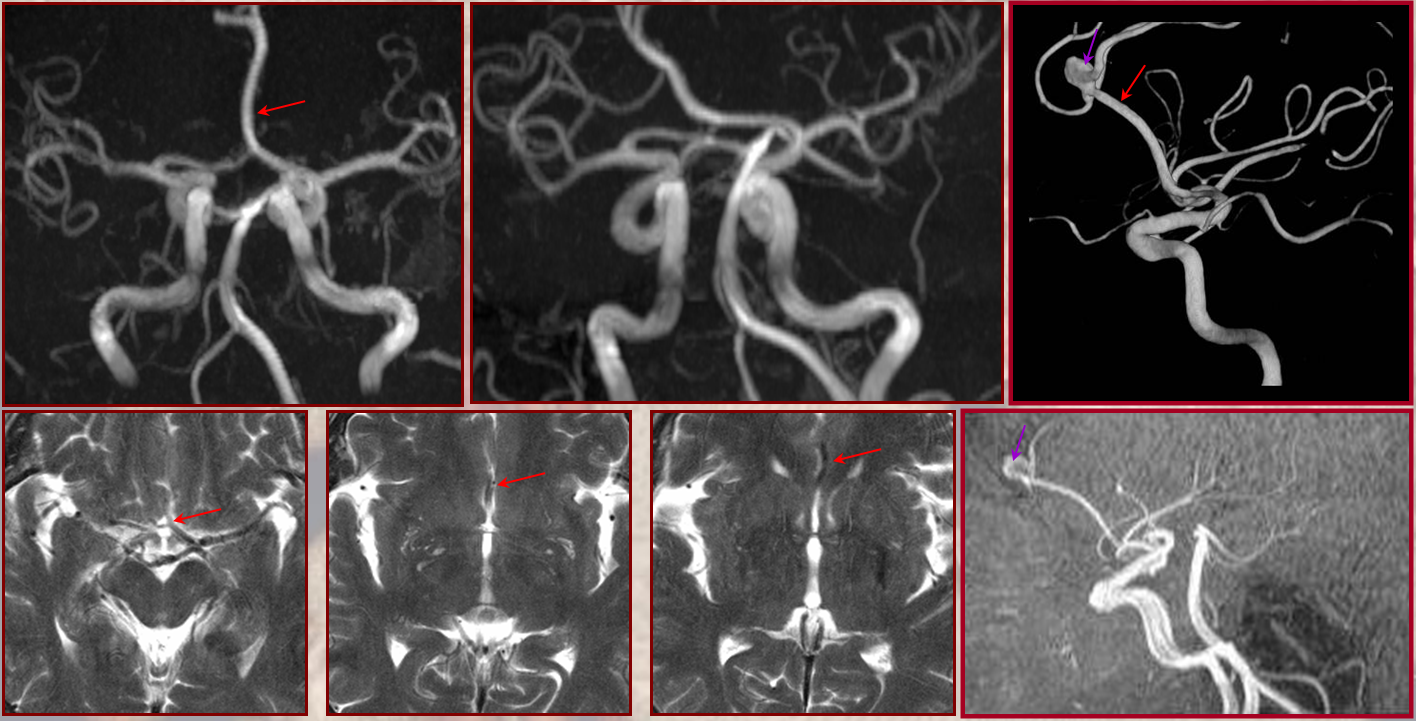
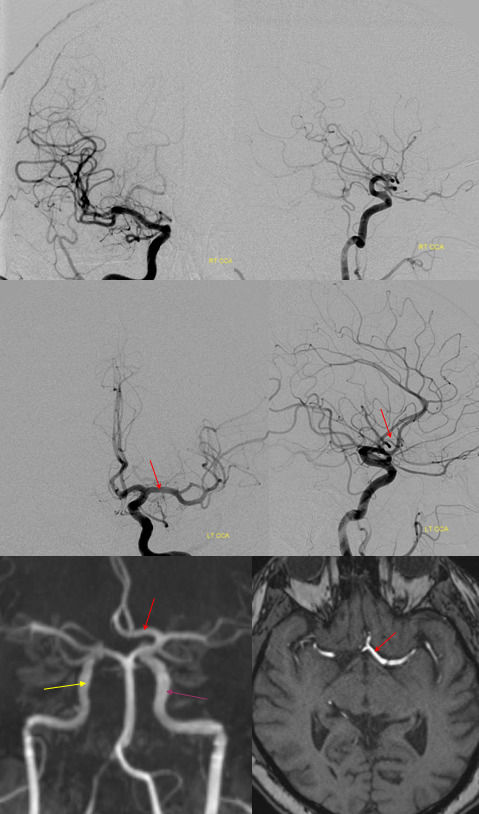
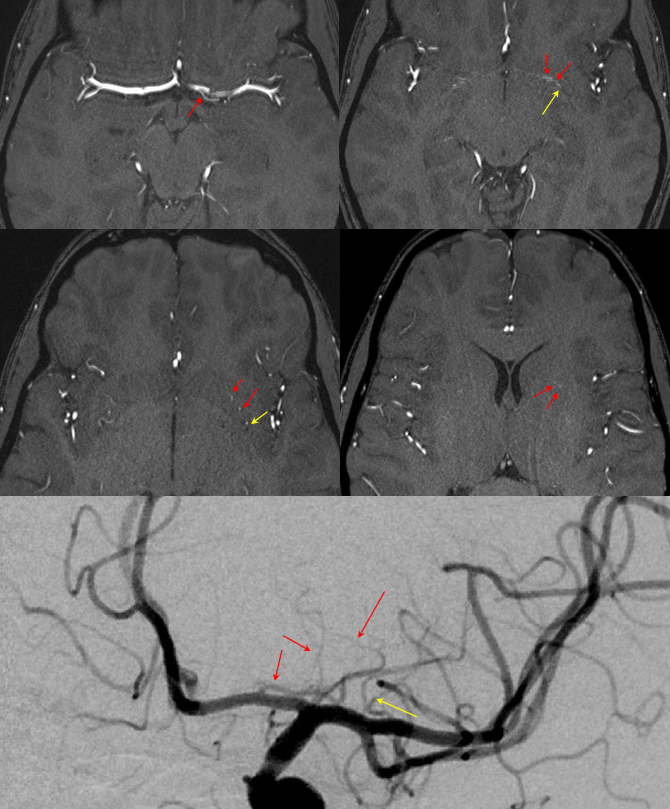
“Unpaired” ACA angiogram and hydrocephalus
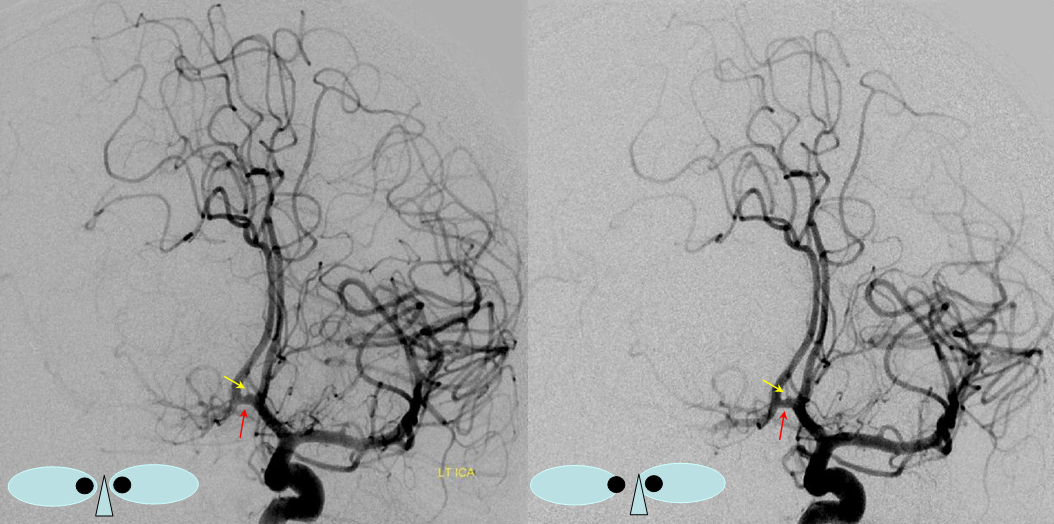
“Unpaired” configuration on the angiogram (red) with bifurcation above the genu (orange). Because a bifurcation is present, the artery cannot be called “Azygous” according to Lasjaunias and Berenstein. A small A1 fenestration is also present (blue). Notice uplifting of the distal pericallosal ACA portion, reflecting hydrocephalus (yellow). The patient suffered from rupture of a thalamic AVM (see posterior choroidal artery)
“Triplicated ACA” Another potential source of costly error is established when a classical “normal” appearance of the bilateral A1 and A2 segments is associated with early takeoff of the the frontopolar branch from the Anterior Communicating Artery. The resulting appearance (see below) can be erroneously interpreted as three A2 segments with 2 Anterior Communicating arteries. Indeed, there are three vessels arising at the ACOM, but one of them is a frontopolar branch, not an A2. Should an aneurysm arise in this region it is critical to understand this anatomy; otherwise the surgeon, coming upon what appears to be the contralateral A2 without realising that the true A2 is yet deeper into the surgical field, may think that the ACOM has been fully explored. In fact, if the aneurysm arises from the ACOM segment distal to the frontopolar branch, the surgeon will not see it and may back off before reaching the true A2.
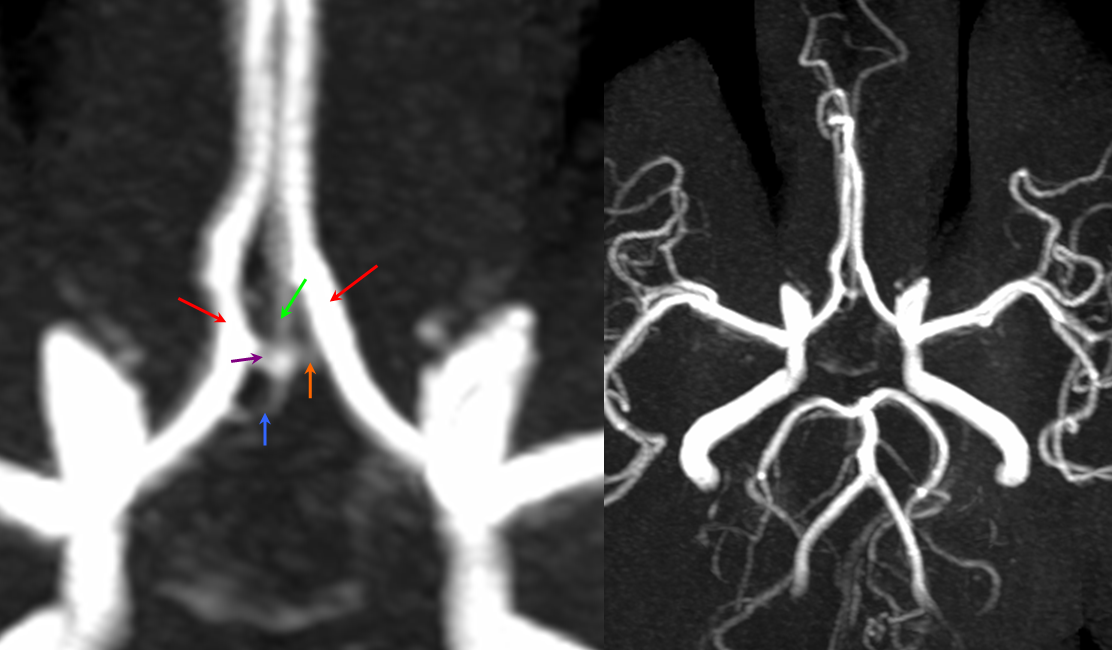
MRA MIP images demonstrating the so-called “ACA triplication” which is in fact a normal disposition with two A2 segments (red) and a smaller frontopolar branch (green) arising from the ACOM (purple and orange). This can be erroneously interpreted as having two ACOMS when there is truly one. Also present is an inferior branch (blue) going toward the region of the optic chiasm.
ACOM origin of frontopolar artery
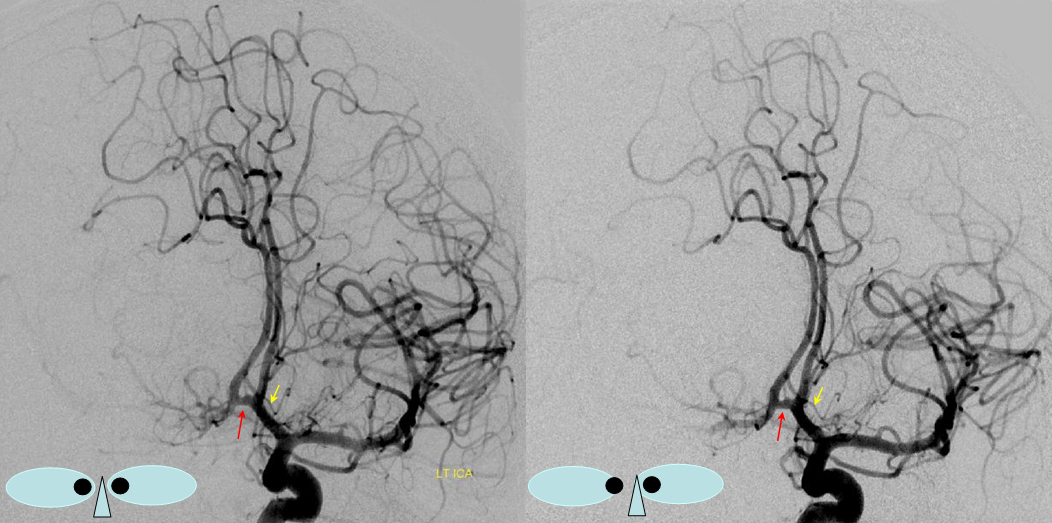
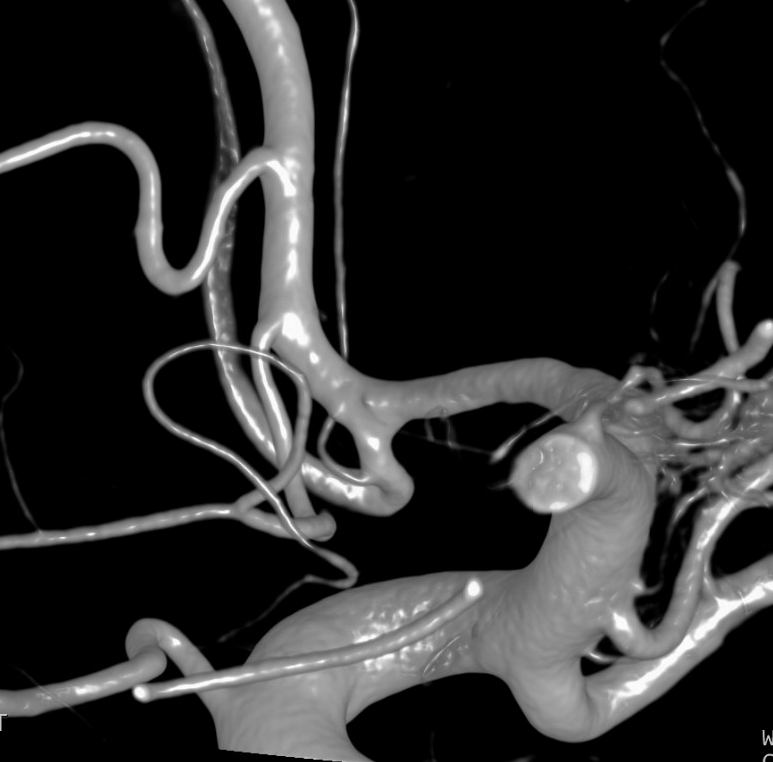
Stereo view of frontopolar artery (yellow) origin from ACOM (red)
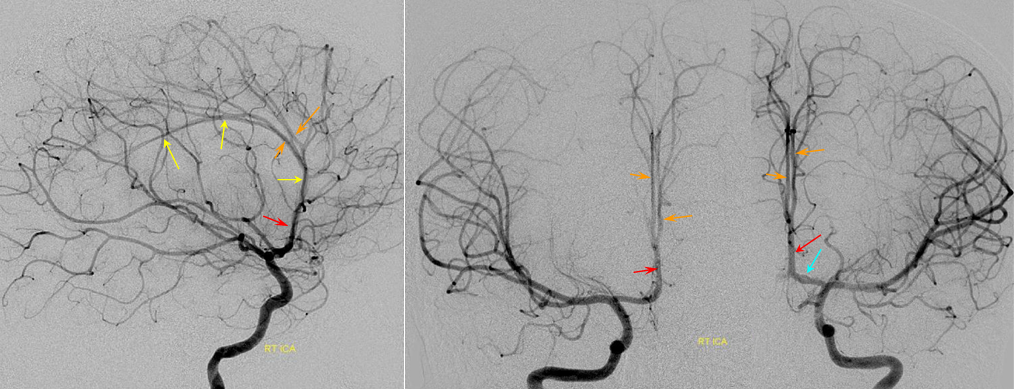
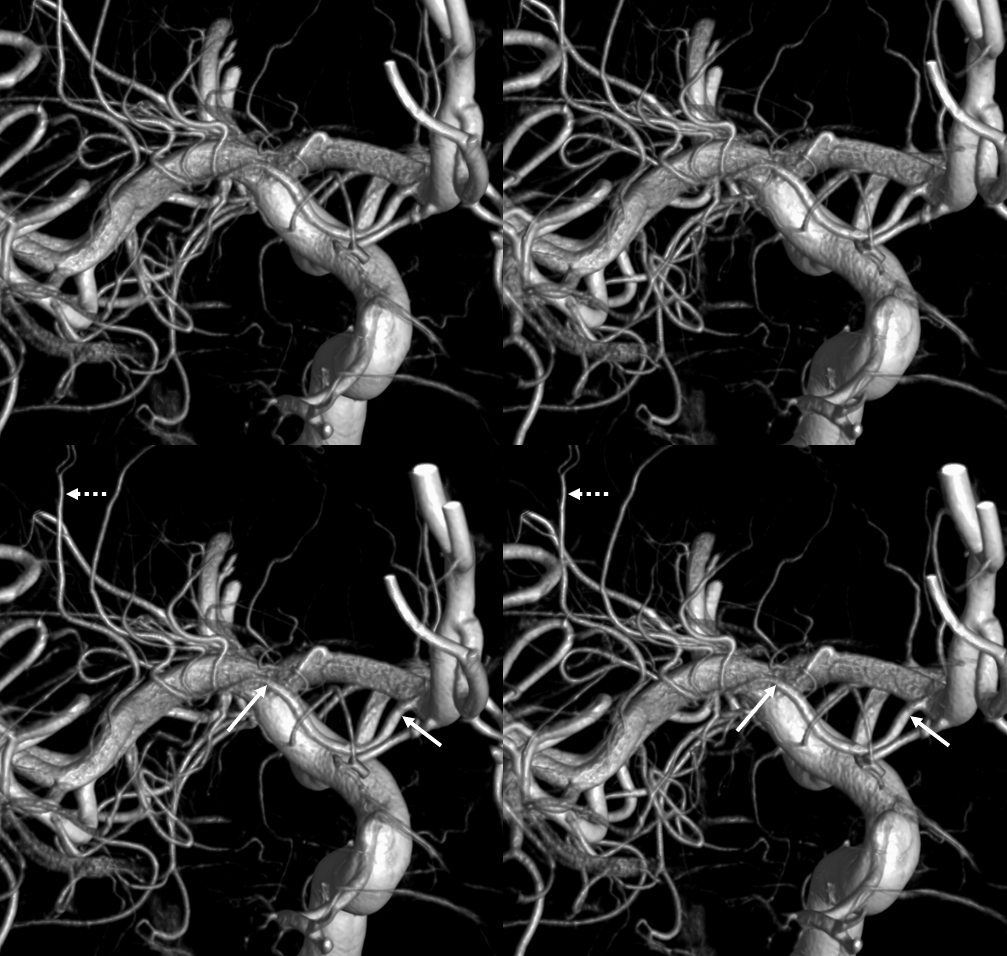
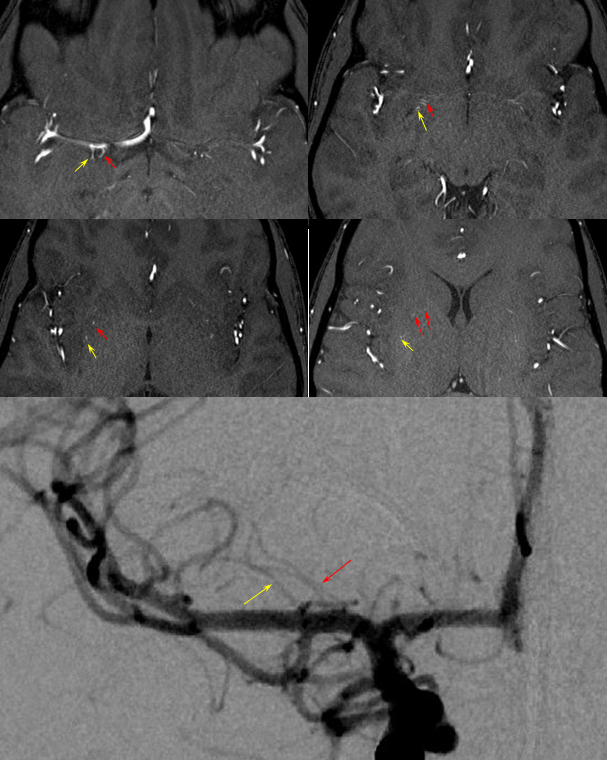
Triplicated ACA — angiographic pitfalls. Angiography of the ACOM region can be challenging, for many reasons. This is one of them. A cursory view of the left and right CCA injections below (top row) may lead one to believe that a normal disposition of two A2 segments exists with a robust anterior communicating artery. A stronger right CCA injection however shows that in fact 3 vessels emerge from the ACOM region, not two! Since all three vessels are difficult to opacify from a unilateral injection, one may arrive at an erroneous conclusion as to the ACOM region anatomy. Right CCA injection on the bottom left and MRA on bottom right of the same patient, in fact, show an early bifurcation of the right ACA into callosomarginal (purple) and pericallosal (red) branches. on the left, a single A2 (yellow) is present, thereby giving a false appearance of “triplication”. The true ACOM is shown in dark blue, whereas the “false” ACOM (a projectional illusion since the right callosomarginal arises from the ACOM region) is marked in light blue. The left A1 reflux is marked in pink.
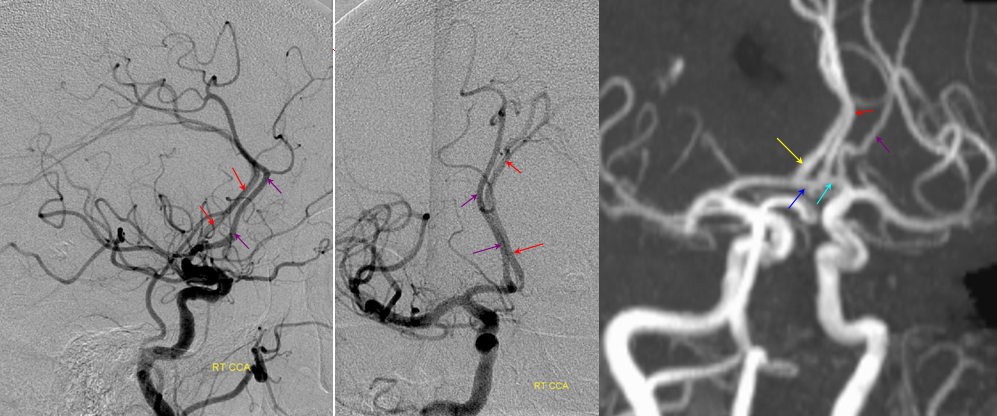
The same patient in lateral with early callosomarginal takeoff (purple) and pericallosal in red. The same MRA image as above.
ACOM Fenestration
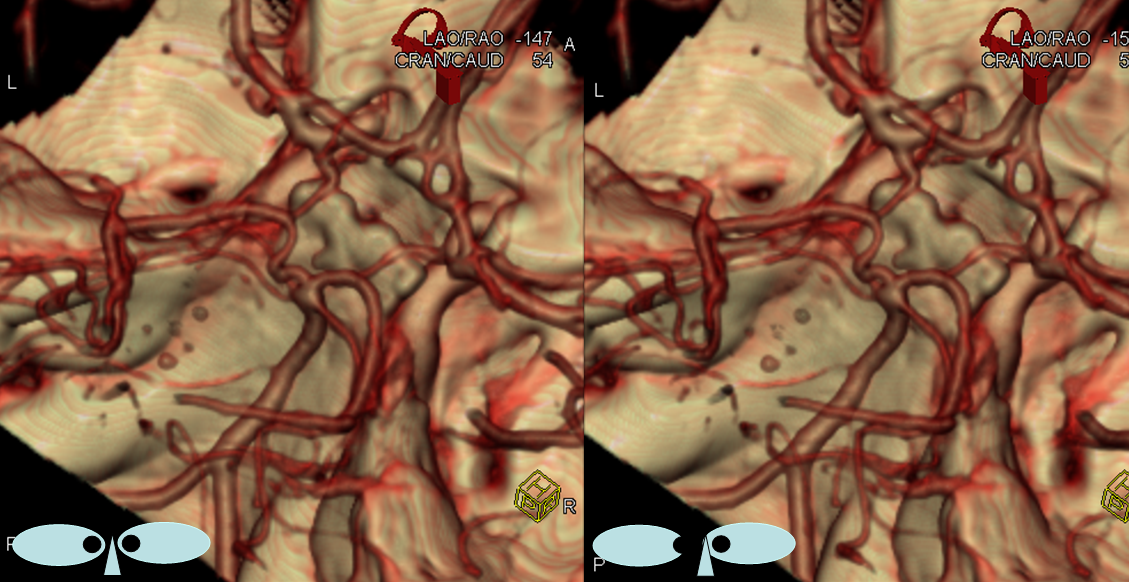
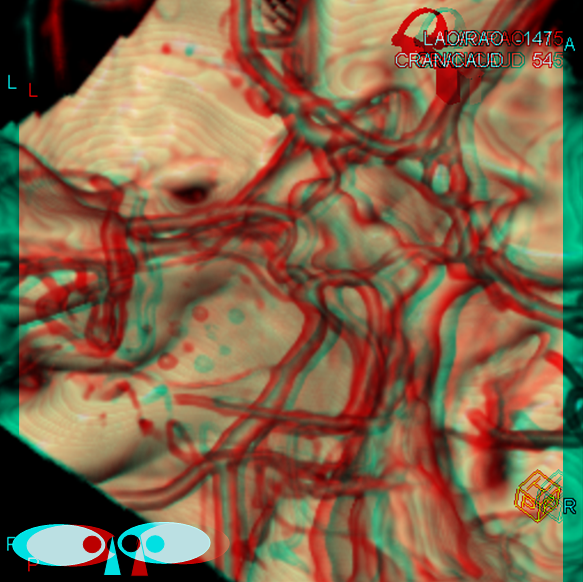
This is a well-known disposition. There are all kinds of fenestration patterns. It is one of the few things that can be tricky to evaluate angiographically because of competing inflow from the other side. It can be also difficult to recognize a fenestration on standard angiographic projections. Caution is highly advised also when evaluating ACOM region on rotational / 3D angiography as competing inflow can result in all kinds of fake-outs (like A1 cutoff looking like an aneurysm). High-quality MR and CT do a very nice job with fenestrations. Much can also be achieved from the under-utilized tool of high-end MRA post-processing. Usually standard volumetric images generated on the MR console are all that is made. However, independent workstation high-end post-processing can be much better. Here is an ACOM seen on standard views, in stereo, of a patient with carotid dissection.
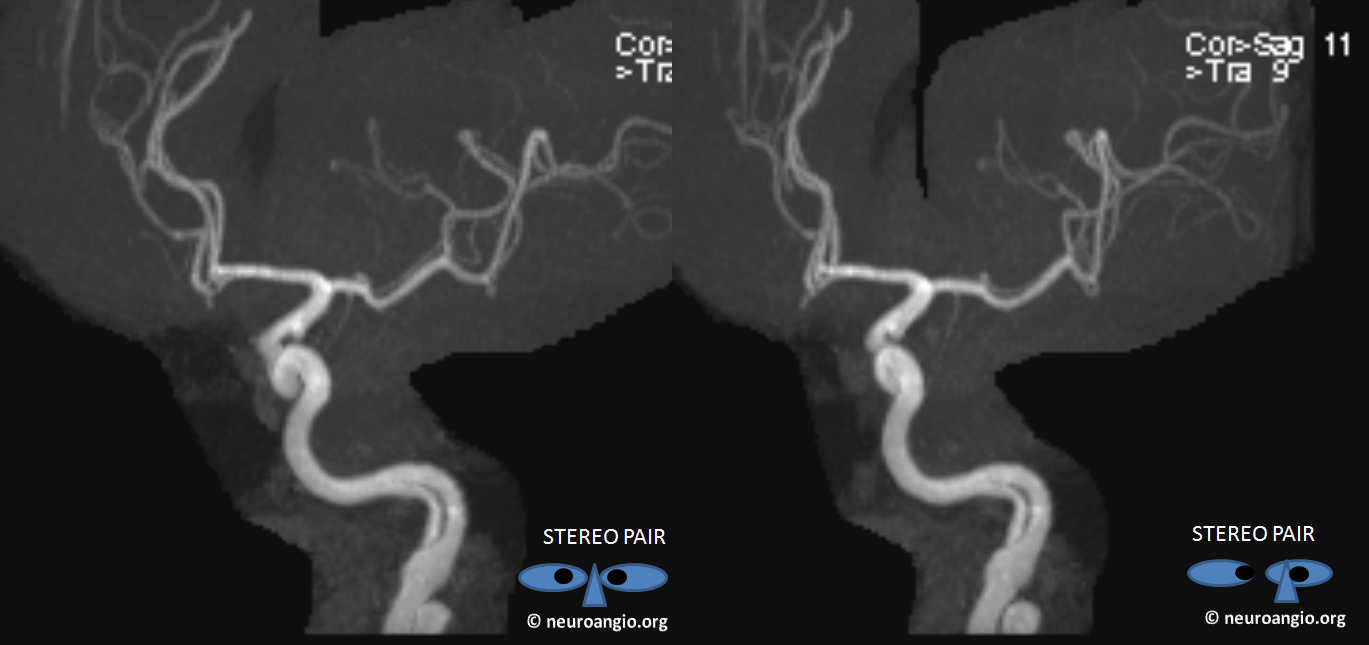
Here is the same ACOM in stereo after real post-processing
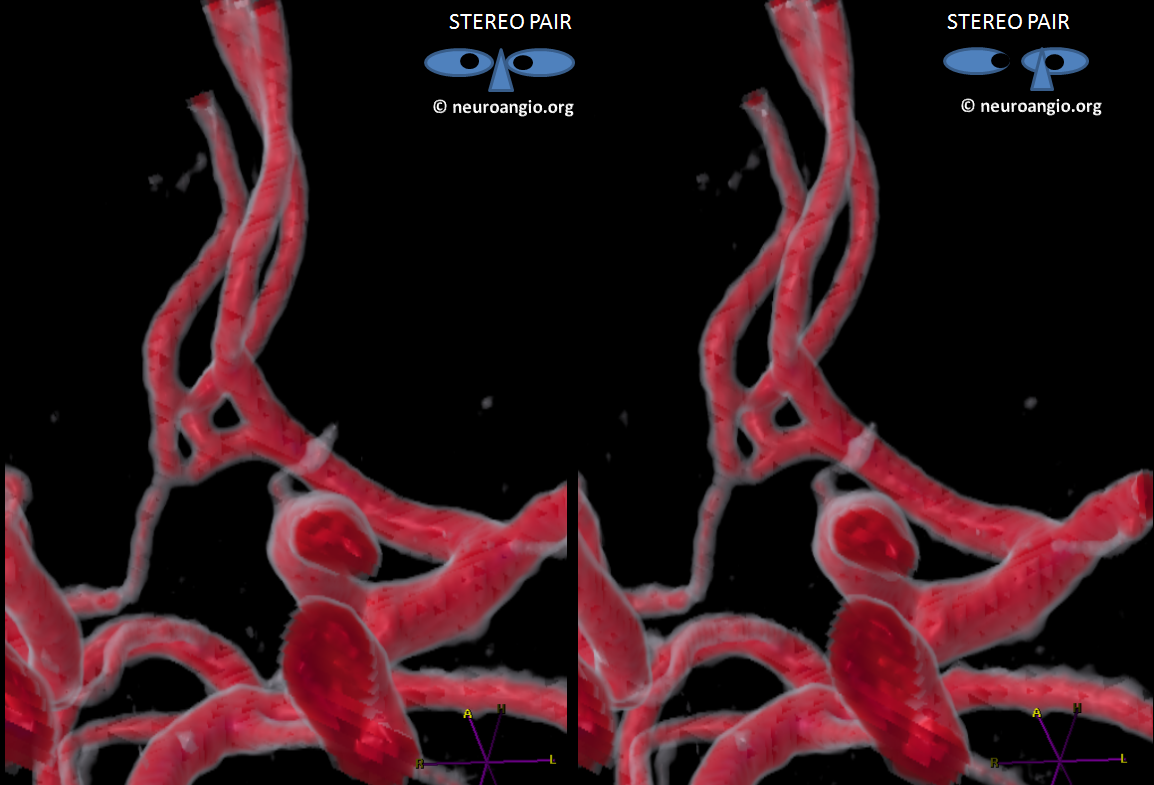
There is a fenestration and an early callosomarginal branch.
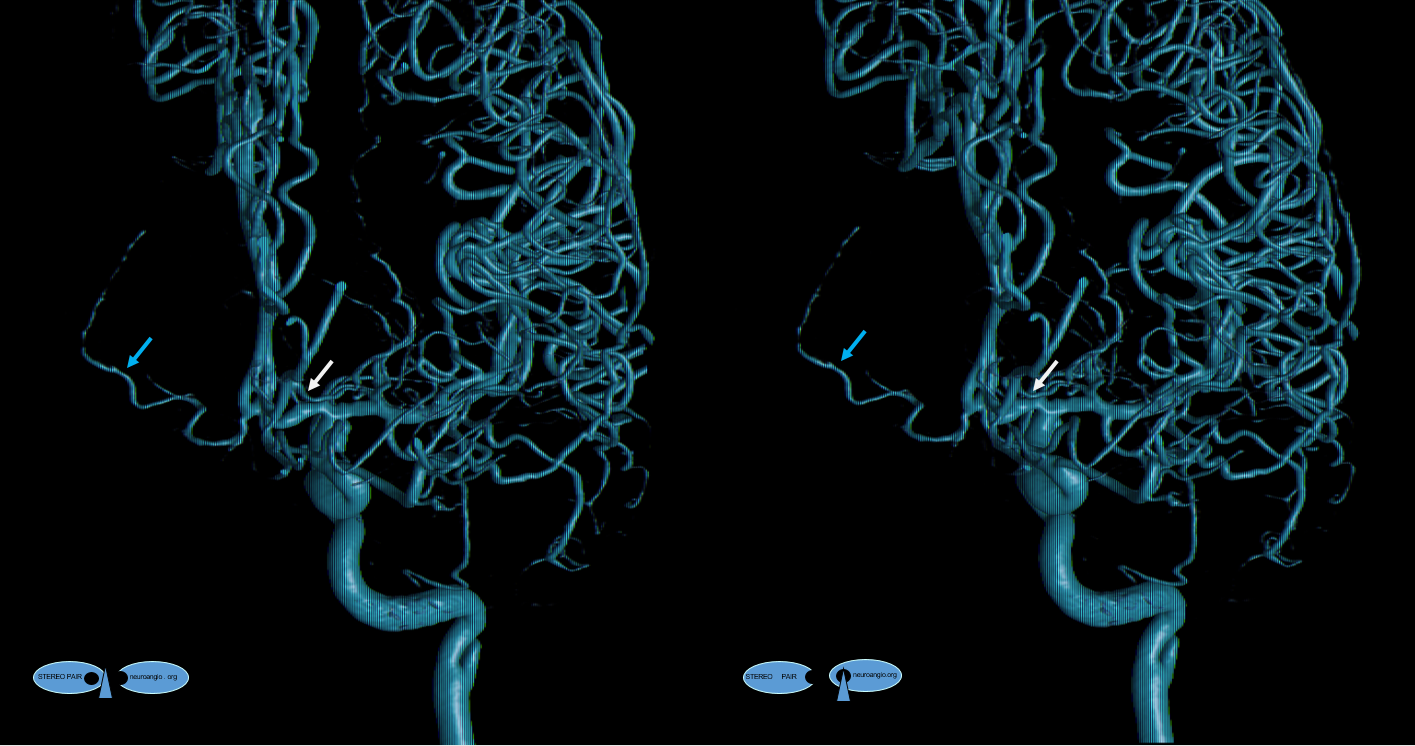
Another example of ACOM fenestration — by Eytan Raz — beautiful DYNA fusion stereos. A subcallosal artery is marked with green arrows — often has an infundibulum as in this case
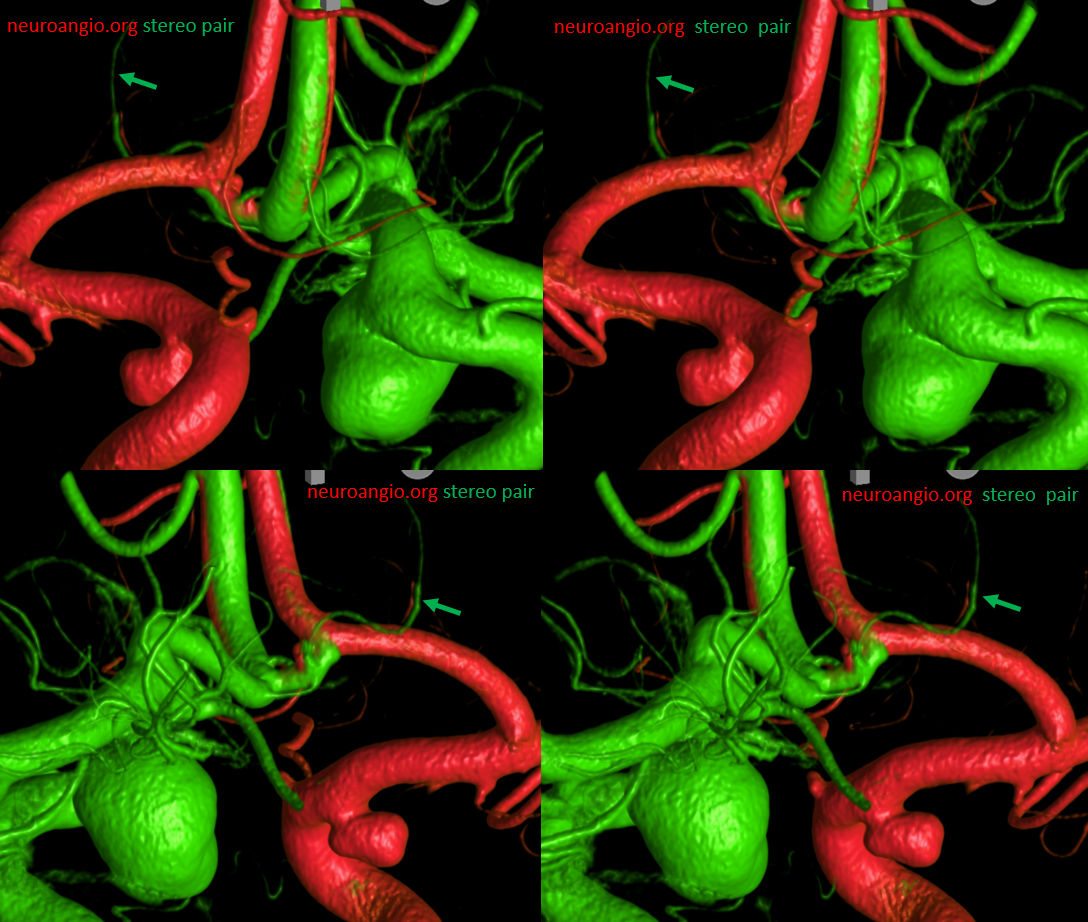
Another view — fenestrations (arrows), subcallosal (dashed arrows) with infundibulum (arrowhead)
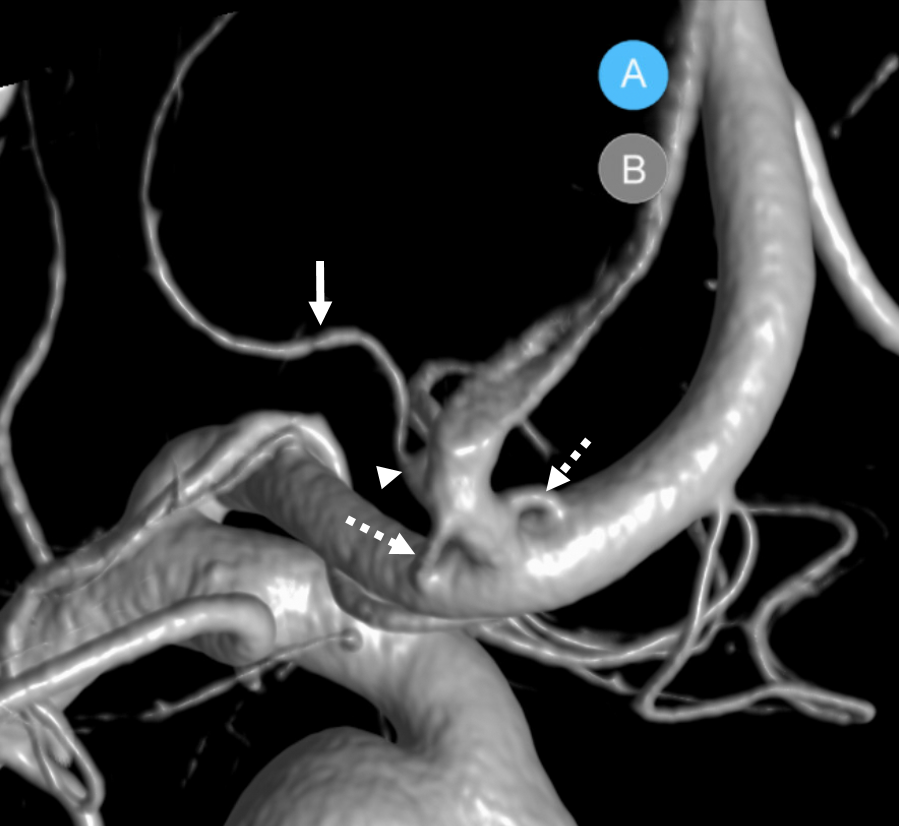
Asymmetric A1 — there is often asymmetry, with dominant A1 segment on one side and a hypoplastic one on the other side. Usually this leads to asymmetry in the size of the carotid artery as well, which sometimes generates confusion as regards potential dissection or long segment stenosis.
Notice that the right ICA (purple) is larger than the left (yellow) since the left side also supplies both ACA territories thru a dominant left A1 (red).
Crossed ACA supply — how about them apples?
More is more — on the spectrum of exceptionally rare… like once in a lifetime. Lets call this X-ACA Case courtesy Dr. Ziad Darkhabani, Corpus Christi Medical Center, TX.
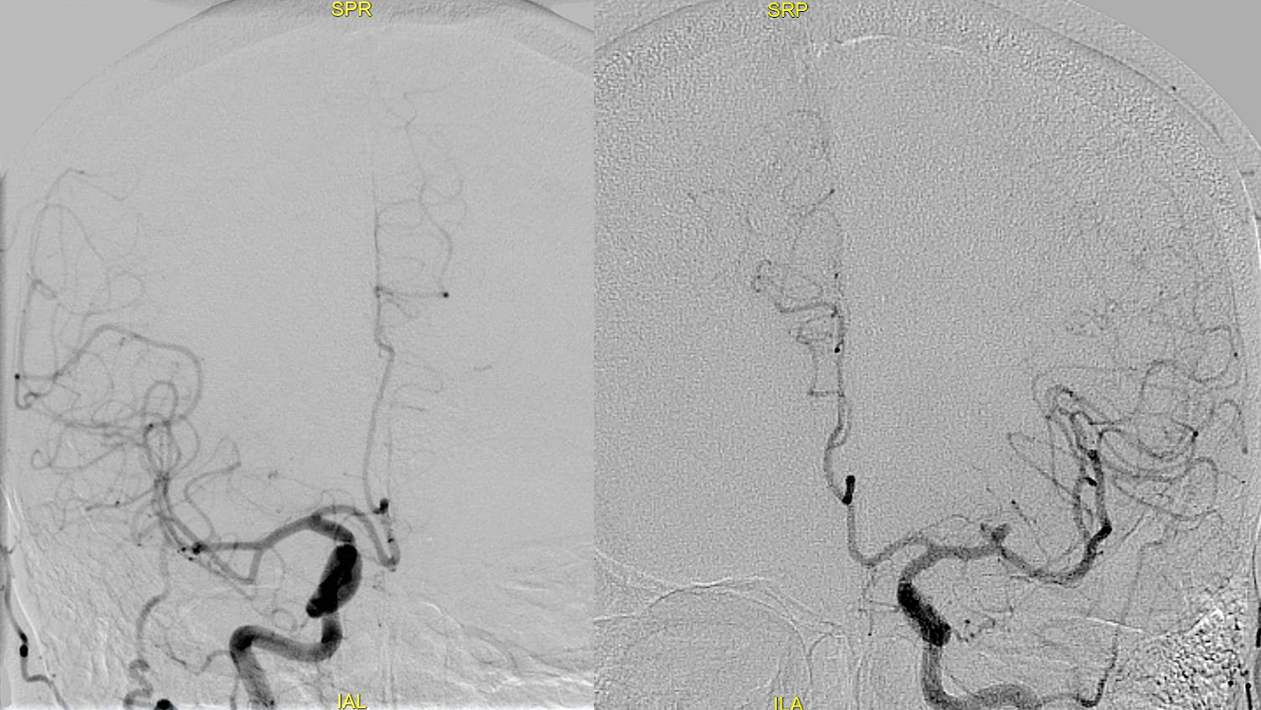
Infraoptic course of the ACA
A relatively rare but very important variant, which illustrates key developmental aspects which also concern the ophthalmic artery. In early embryonic development, orbital structures are supplied by two vessels, both of which do not originate from the “adult” location of the ophthalmic. Instead, a dorsal ophthalmic artery arises from the region of future ILT, and second ventral ophthalmic artery extends from the anterior cerebral artery (ACOM region), underneath the optic nerve, and through the optic canal into the orbit. Occasionally, the dorsal ophthalmic artery persists, with several examples shown in the ophthalmic artery and ILT sections. Extremely rarely, the ventral ophthalmic artery can persist as well. More commonly, however, the ventral ophthalmic artery conduit persits as the “A1 segment” of the ACA, as in this case, and takes an infraoptic course. It appears as though the ICA bifurcated early — at the ophthalmic segment — such that everything distal to the “early” ICA bifurcation may be perceived as the MCA — implying that both PCOM and A. Choroidal arise from this M1 segment. This, of course, is an incorrect interpretation — in fact, the “classical” A1 segment is developmentally hypoplastic, and is compensated by its collateral ventral ophthalmic conduit, which functions as the A1 segment, such that both PCOM and A. Chor. arise exactly as they should, and the M1 segment is defined as the vessel distal to the choroidal.
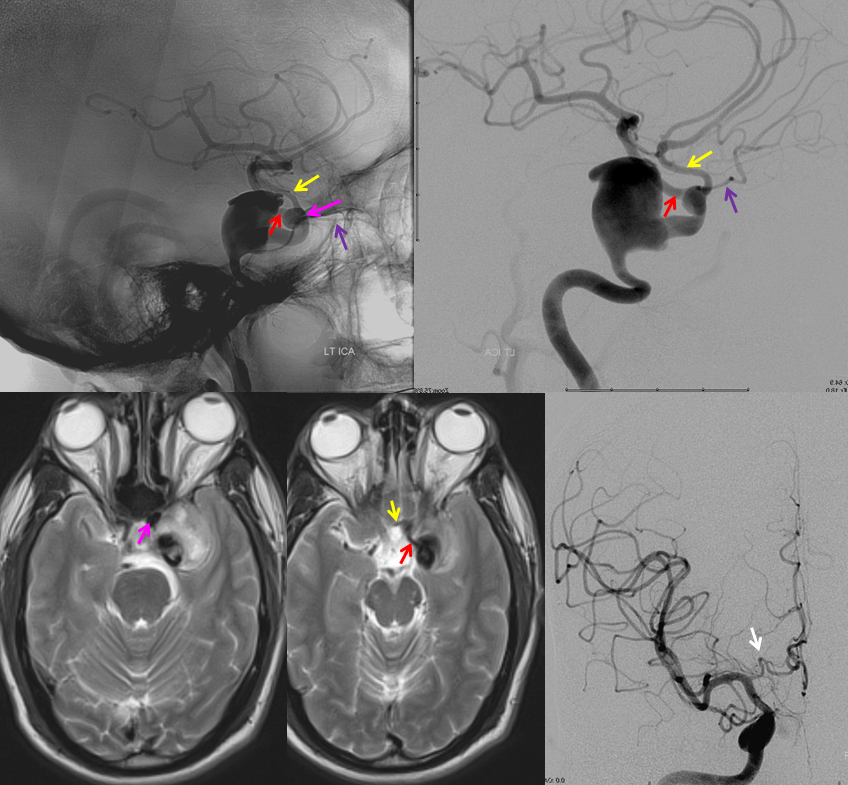
Angiographic and MRI images demonstrating a giant, partially thrombosed cavernous segment aneurysm in association with “early takeoff” and infraoptic course of the left ACA (yellow). MCA is red. A second aneurysmal dilatation (pink) at the trifurcation of the ICA, ACA, and ophthalmic artery (purple) is present also. Frontal projection of contralateral right ICA injection shows redundant course of the right A1 segment (white arrow), which should be recognised as a distinct anatomical variant in bilateral A1 segment development, correlating with the more obvious issues on the left side.
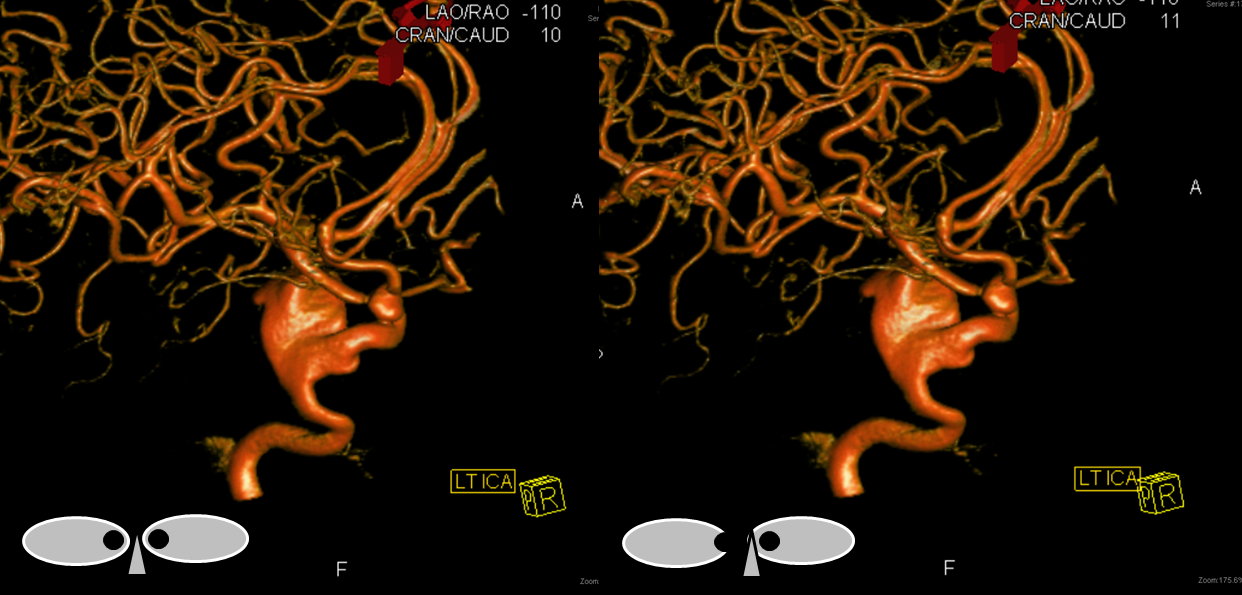
Stereo pair of rotational volumetric dataset in the same patient. Notice normal location of the anterior choroidal artery, once it is understood that the vessel distal to ACA takeoff and proximal to the choroidal is still the ICA, not an M1 segment. 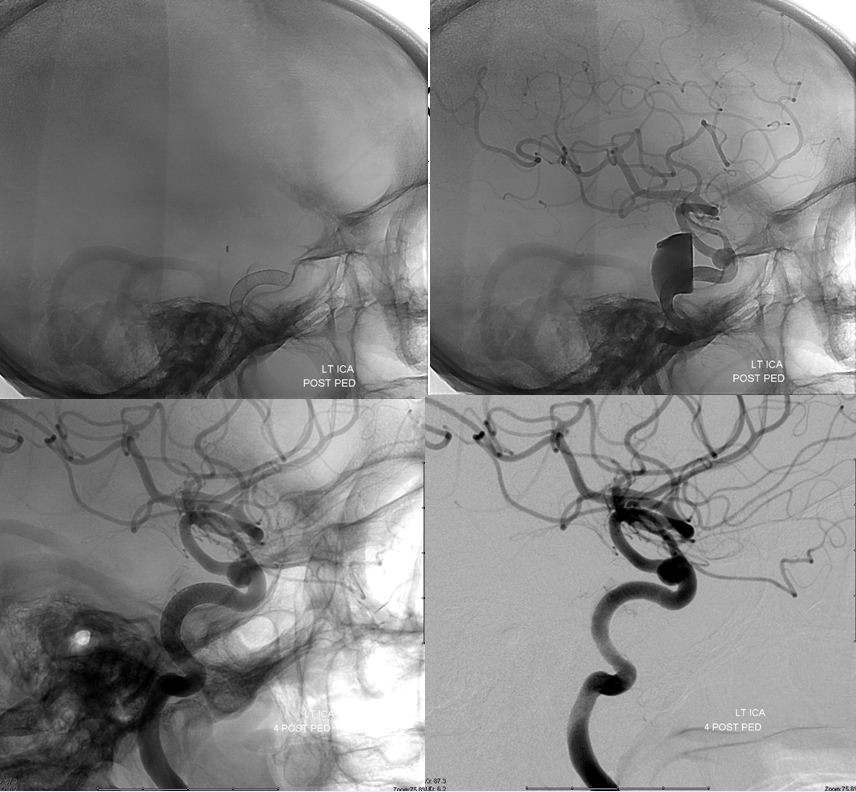
Top row lateral DSA immediately post Pipeline embolization of the cavernous segment aneurysm. Bottom row 4 months post embolization shows cure of cavernous aneurysm. The anterior choroidal artery is well seen.
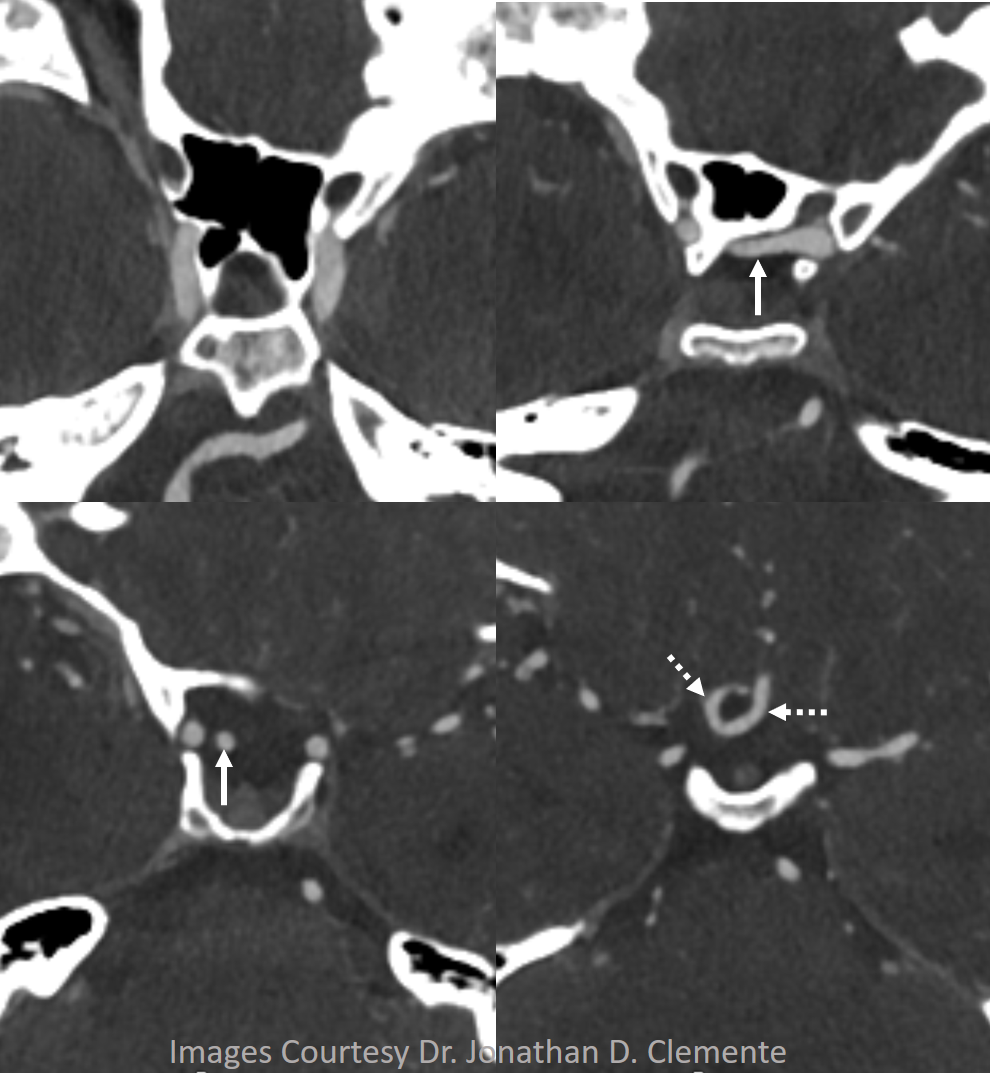
Here is another example of an infraoptic A1 segment of the ACA on cross-sectional imaging, where it is particularly easy to see relationship between the infraoptic A1 (white arrows) and the optic nerve
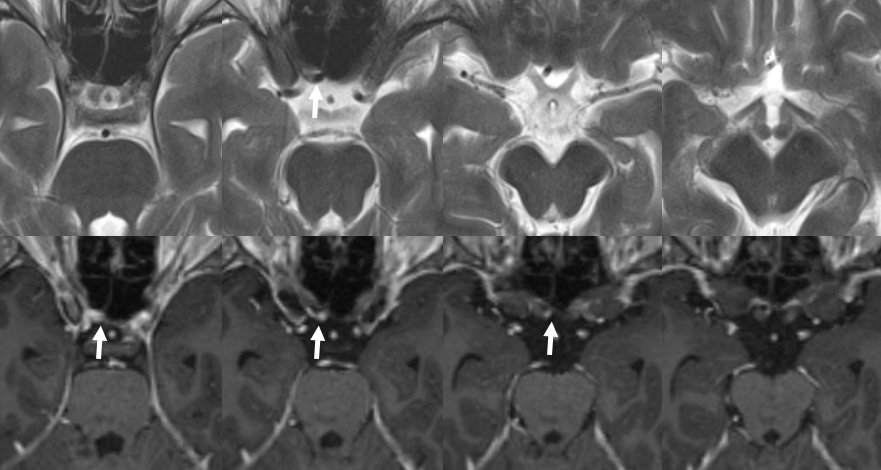
Axial CTA
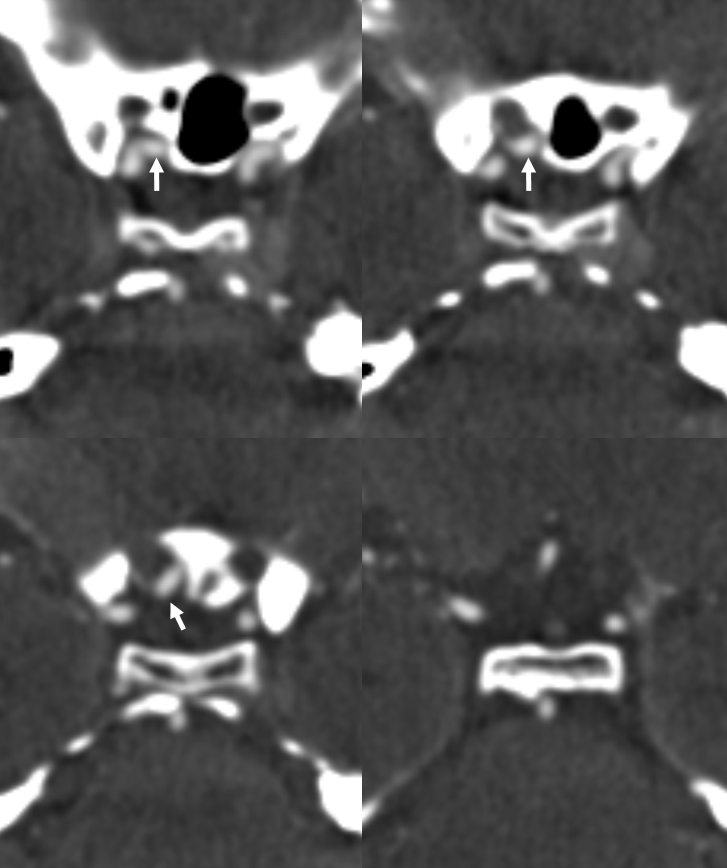
Coronal CTA
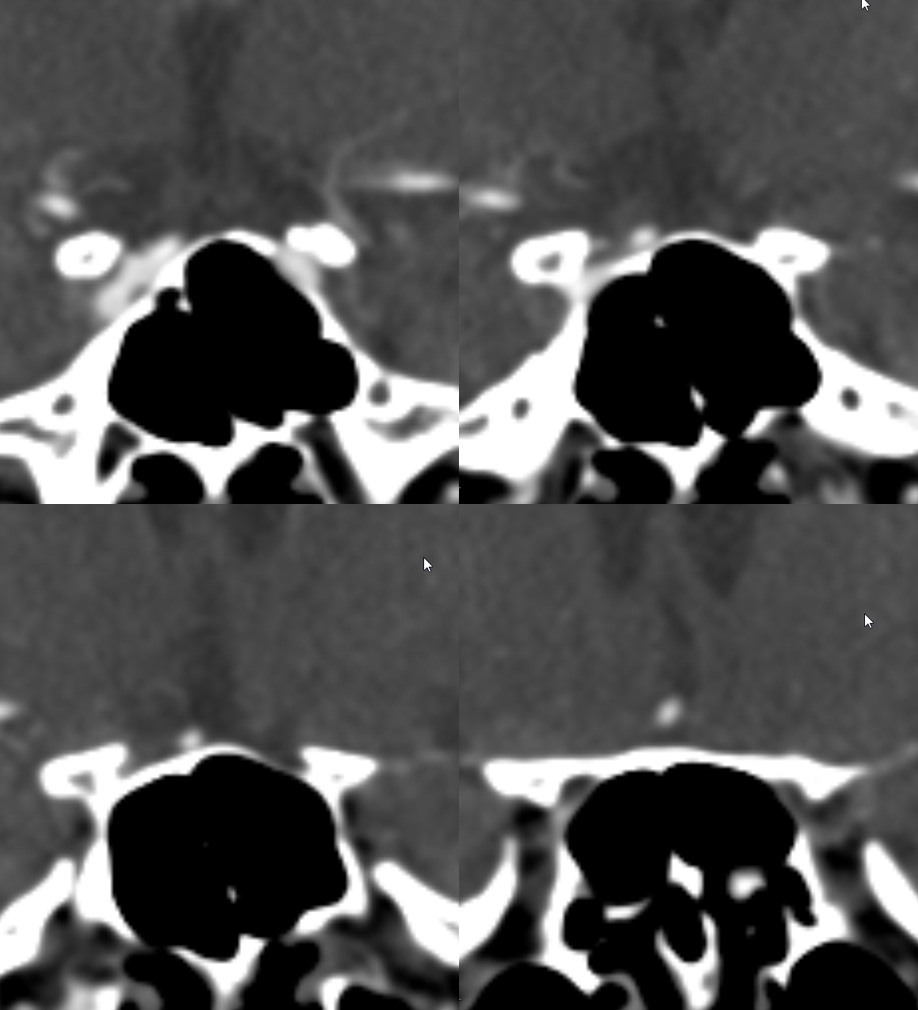
Yet another example, in a patient with bilateral infraoptic A1s, and also has a left aberrant carotid artery (not shown). Notice in this case how on the right (CTA VR view) both infraoptic (smaller vessel) and “classic” supraoptic (larger vessel) A1 segments are present. On the left, a small infraoptic A1 is partially obscured by the PCOM that we wanted to leave in place for reference
Colored stereo anaglyph view
Black and white anaglyph view
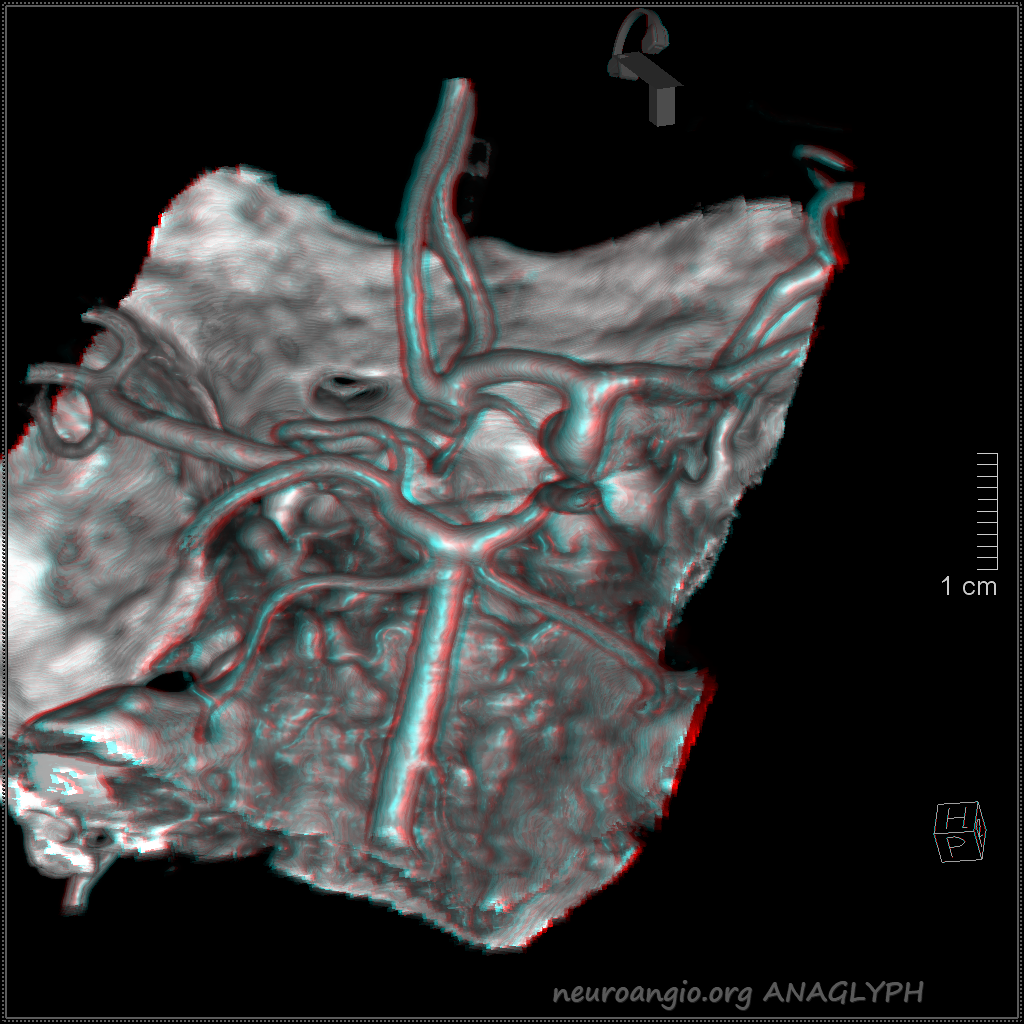
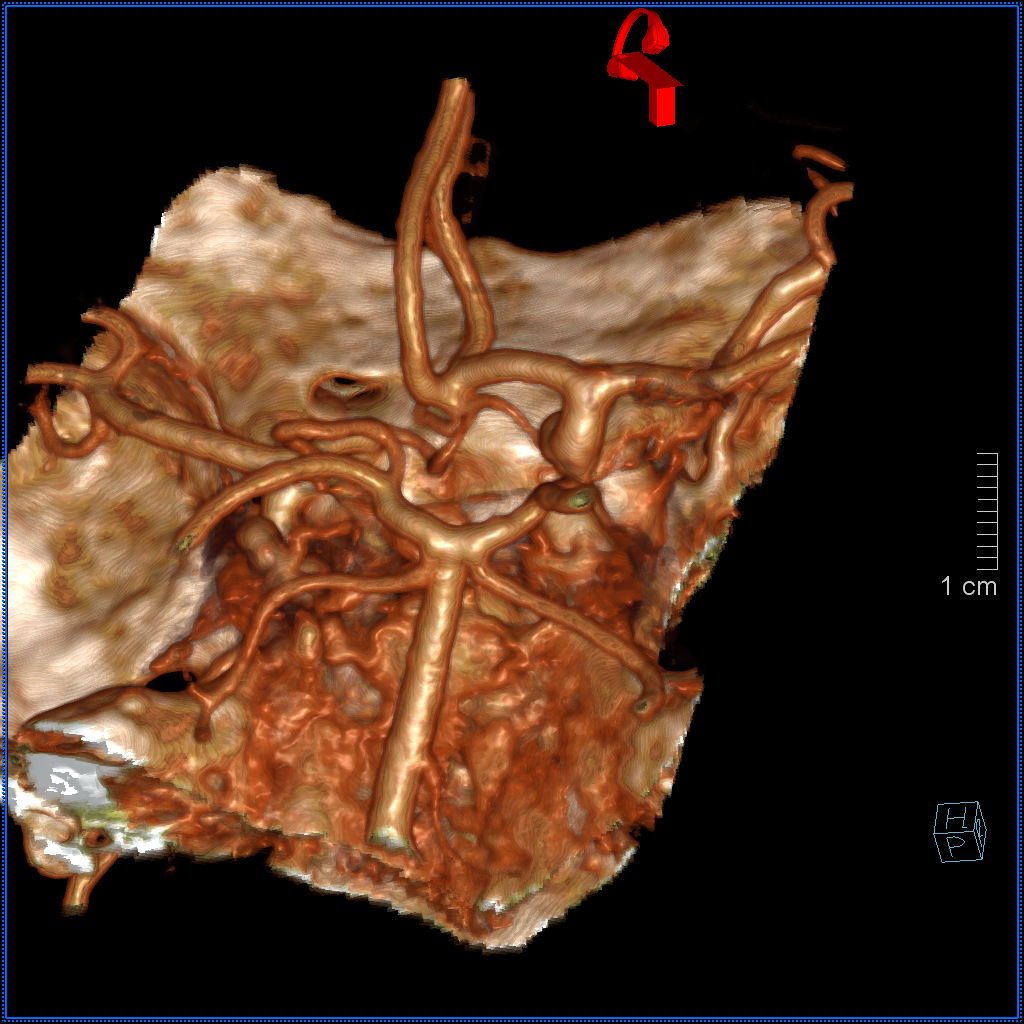
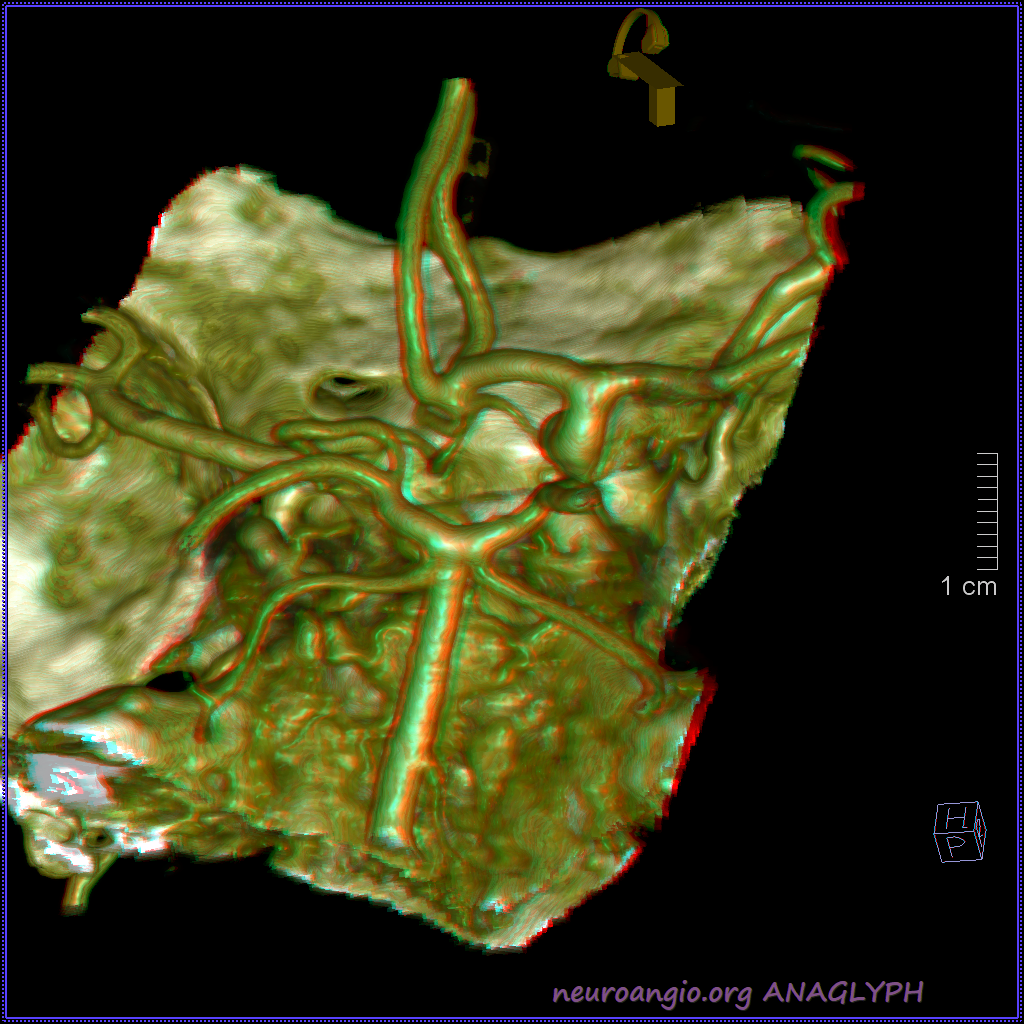
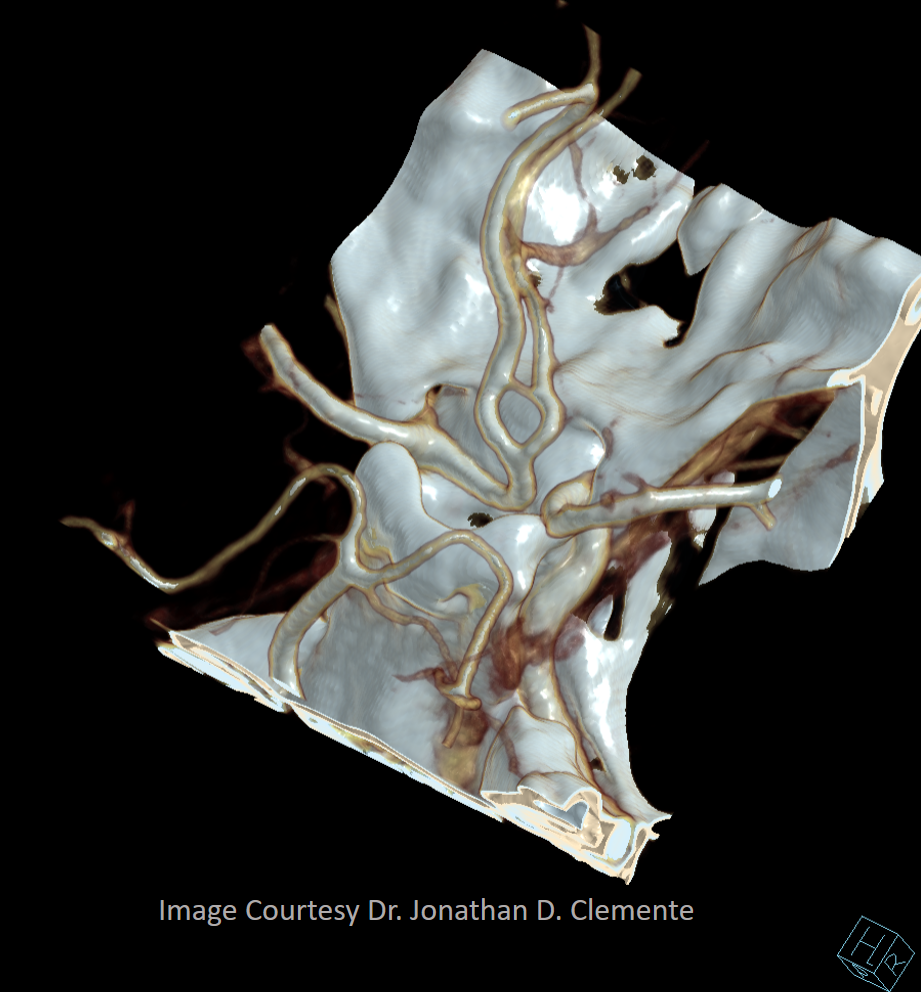
Another example on a gorgeous quality CTA, courtesy Dr. Jonathan D. Clemente. Infraoptic unpaired A1 (arrow) supplies both A2s (dashed arrows)
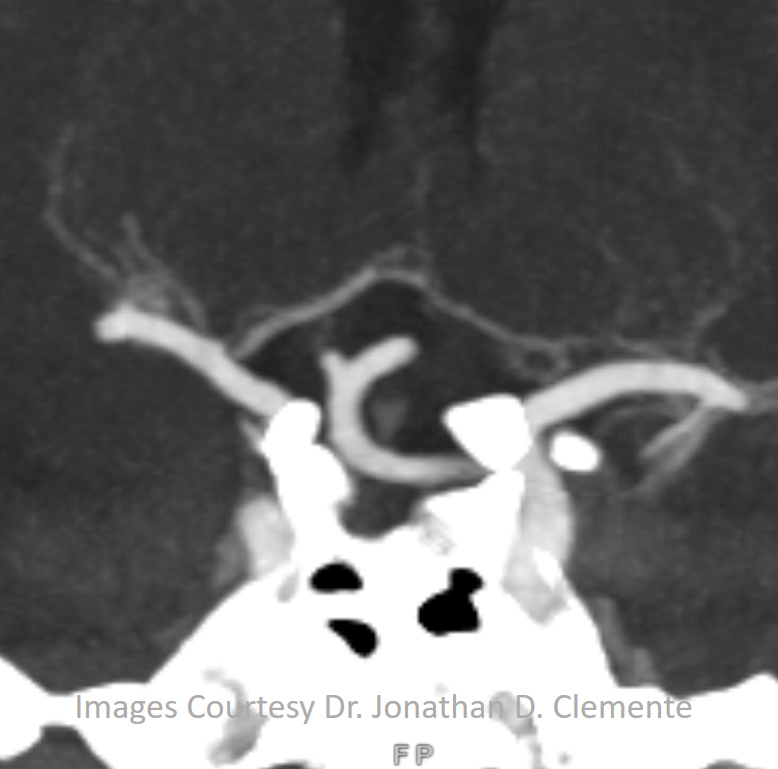
Coronal MIP
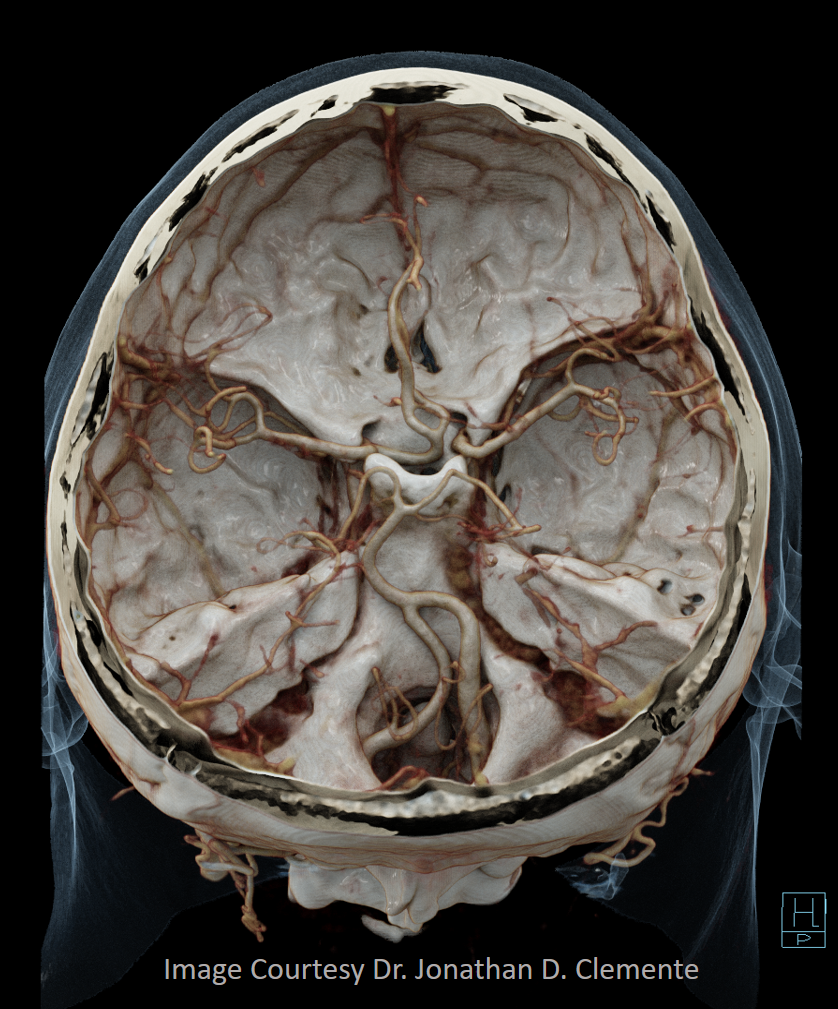
Some really awesome Cinematic Renderings, also highlighting a fenestrated ACOM region
Primitive Olfactory Artery
Another “variant” — the olfactory artery most often comes off somewhere around proximal A2. It is indeed a phylogenetically old vessel — smells and memories of them, supported by ancient 3-layer cortex. Occasionally, the ACA takes a detour down olfactory memory lane before return onto the beaten path. A nice embryology plug. Here is primitive olfactory course (arrow) with an aneurysm.
Video
Immediately after Pipeline Embolization
Here is another one — without aneurysm… There is a fusiform basilar one in this case (not shown), in addition to the dissecting cervical ICA though
The left side is “normal”
Recurrent Artery of Heubner
Famous artery. Usually comes off the A1 or on occasion A2 or ACOM. “Recurrent” because it goes “back” laterally along the A1 segment towards the terminal ICA, so it often looks like a small artery running alongside and above the much bigger A1. It is simply one of the larger medial perforator arteries arising from A1 and M1 segments to head towards the basal ganglia. It happens to be usually conspicuous and therefore has proportionally larger surgical and endovascular implications to preserve it. It is also instructive in terms of MCA embryology — cases of “MCA duplication” are often not MCA duplication but a particularly large Heubner which supplies much of the basal ganglia and sometimes cortical territory, and therefore looks like another ICA. Going back to amphibians and fishes, where an MCA-like vessel is first recognized, it turns out that MCA develops from coalescence of multiple smaller perforator-type vessels which assume prominence with phylogenetic enlargement of the brain volume to capture cortical surface territory. It is not difficult to conceptualize that on occasion instead of a single MCA trunk, two vessels may develop to “split” the MCA territory, thereby earning the name of “duplicated MCA”. The other “MCA” is usually another perforator-like vessel, i.e. Heubner. As with any vascular arrangement, the size of the Heubner will vary depending on development of collateral vessels to the same area — it will be small when other medial perforators are well-developed, and vice versa.
This idea of a spectrum — that lenticulostriates are a family — with “medial” and “lateral” designations being very useful in regard to territory — but coming at expense of appreciation that they are all part of the same continuum embryologically — and that case-by-case arrangements dictate territory and therefore infarct size — is the basis of our “spectrum” approach to anatomy. The lenticulostriates as a whole are in balance. Below is an illustration of this concept — see our MCA JNIS publication for more.
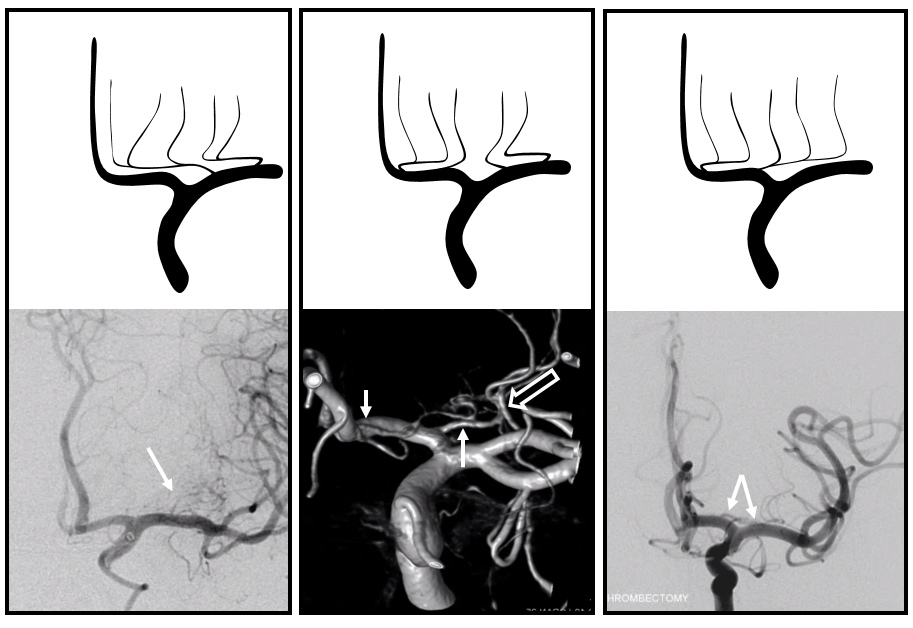
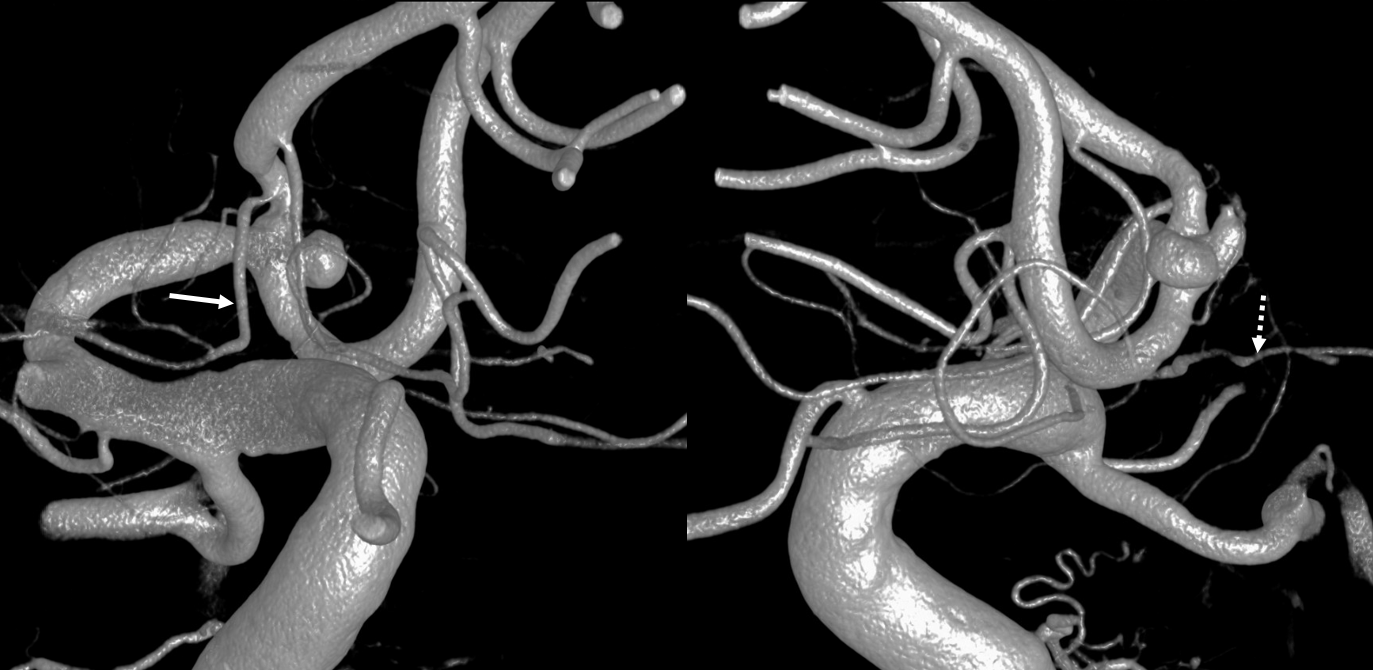
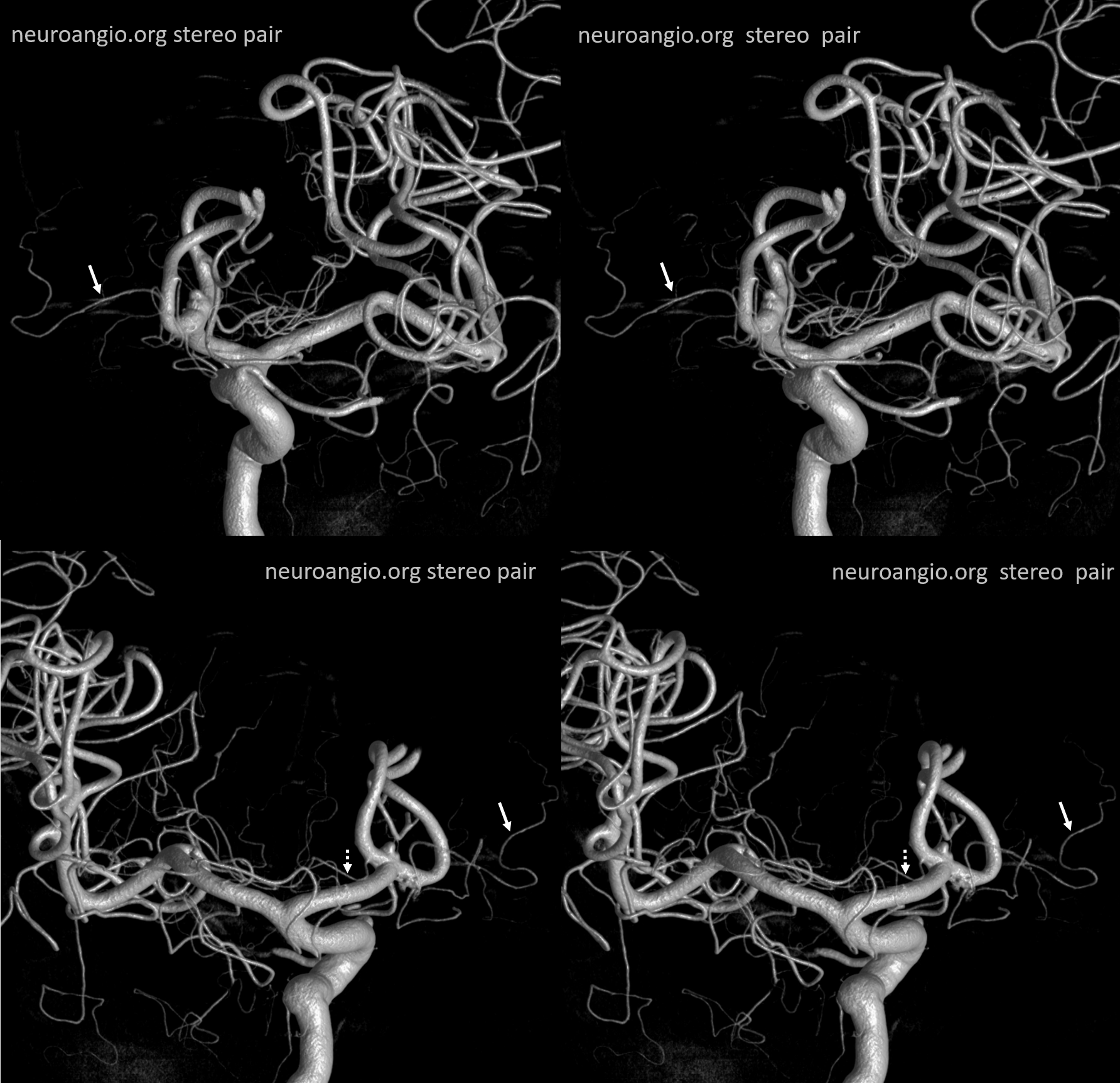
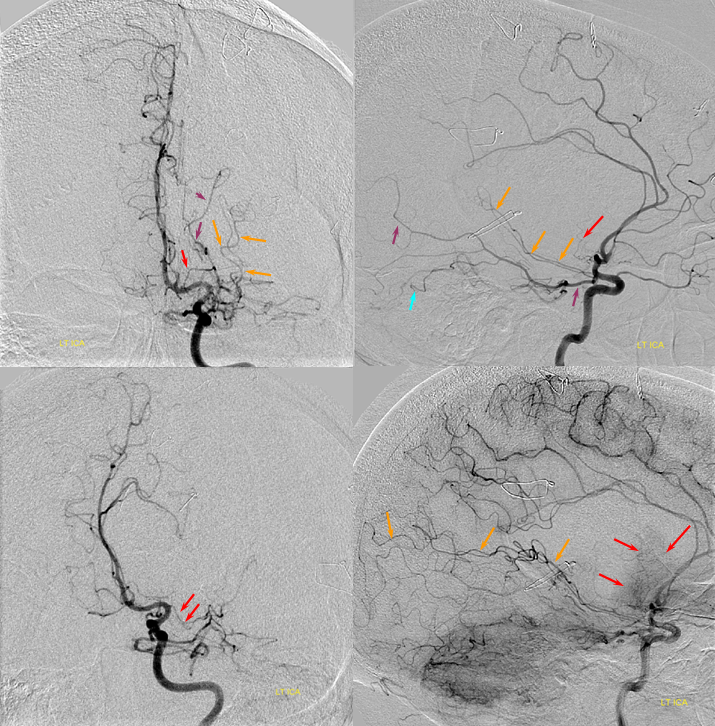
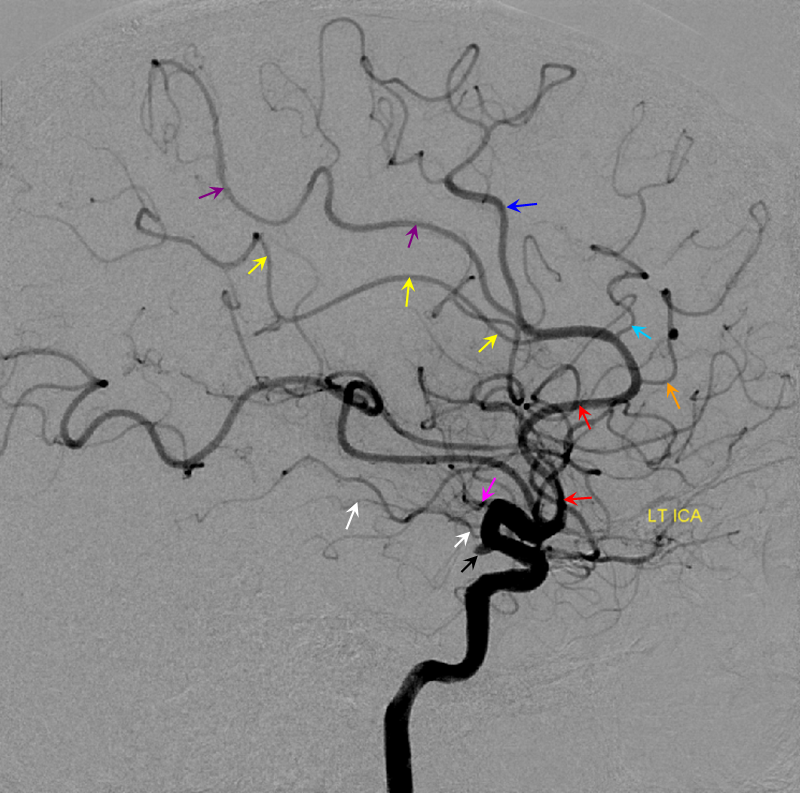
Below is an example of global analysis. Patient presents for evaluation of an irregular carotid terminus aneurysm on the right and a suspected small anterior choroidal aneurysm on the left. Stereos, fusion Cone beam CT video and fusion MIPs are below. There is a highly dominant A1 segment medial perforator on the LEFT supplying all lenticulostriate territory (top stereo figures — looking from posterior, so this is left ICA injection). Bottom images — left ICA is red, right is green. Classical smaller Heubner on right, with a classical lateral lenticulostriate origin. Left (green) — dominant A1 segment “Heubner” like vessel supplying both medial and lateral lenticulostriate families. But not all of them…
There is also a nice ACOM fenestration
Now look at the MIP fusions — there is indeed a proximal RIGHT A2 origin vessel (yellow, since its opacified by both injections) which is the “true” Heubner — medial-most perforator. It supplies a portion of the medial territory, with the rest supplied by the large A1 common origin perforator seen above.
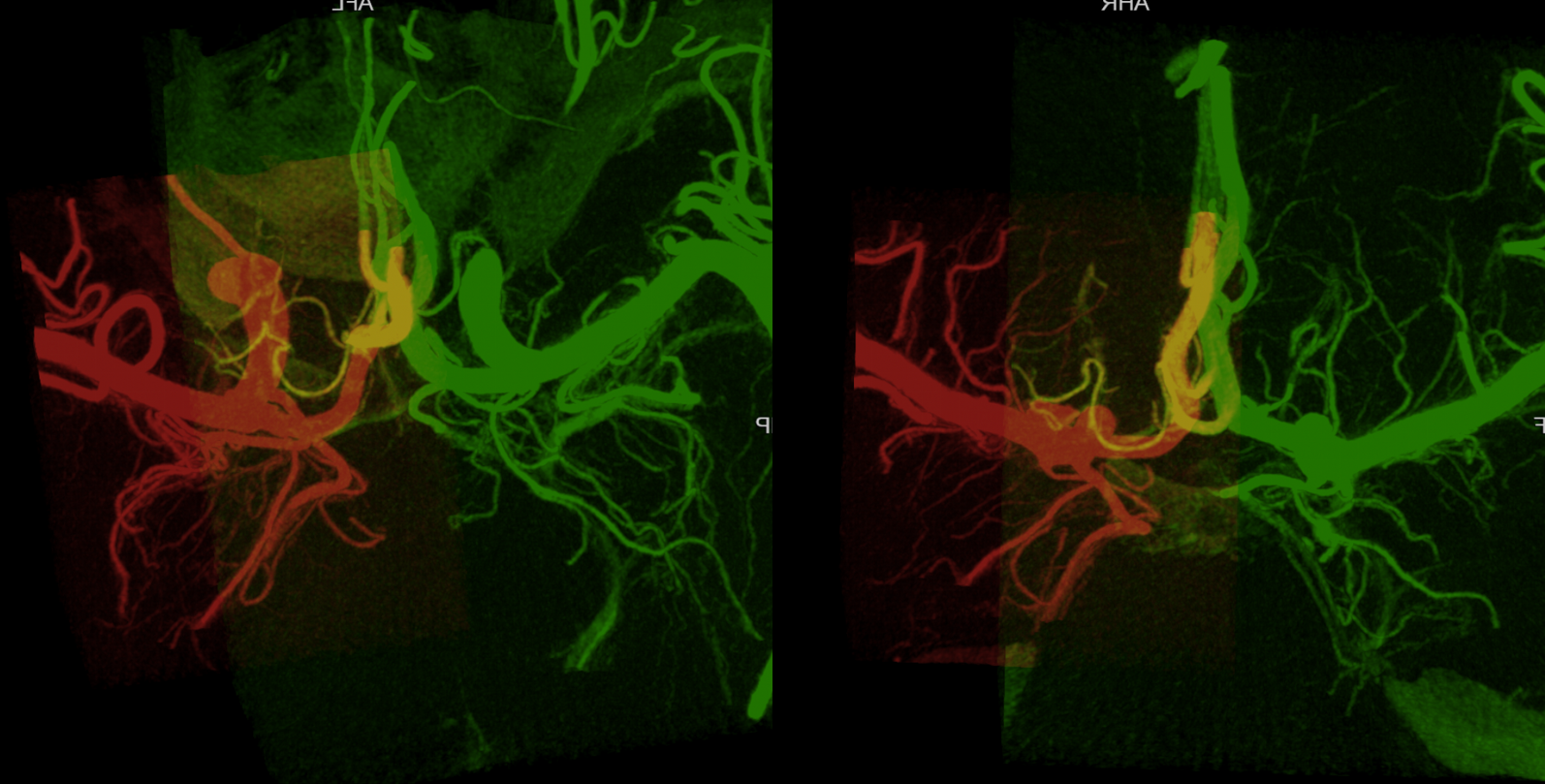
That’s the spectrum of variation — and how to analyze it.
Dominant Heunber takes care of medial and most lateral lenticulostriate territory (arrows). Only the most lateral branch (dashed arrows) is M1 origin
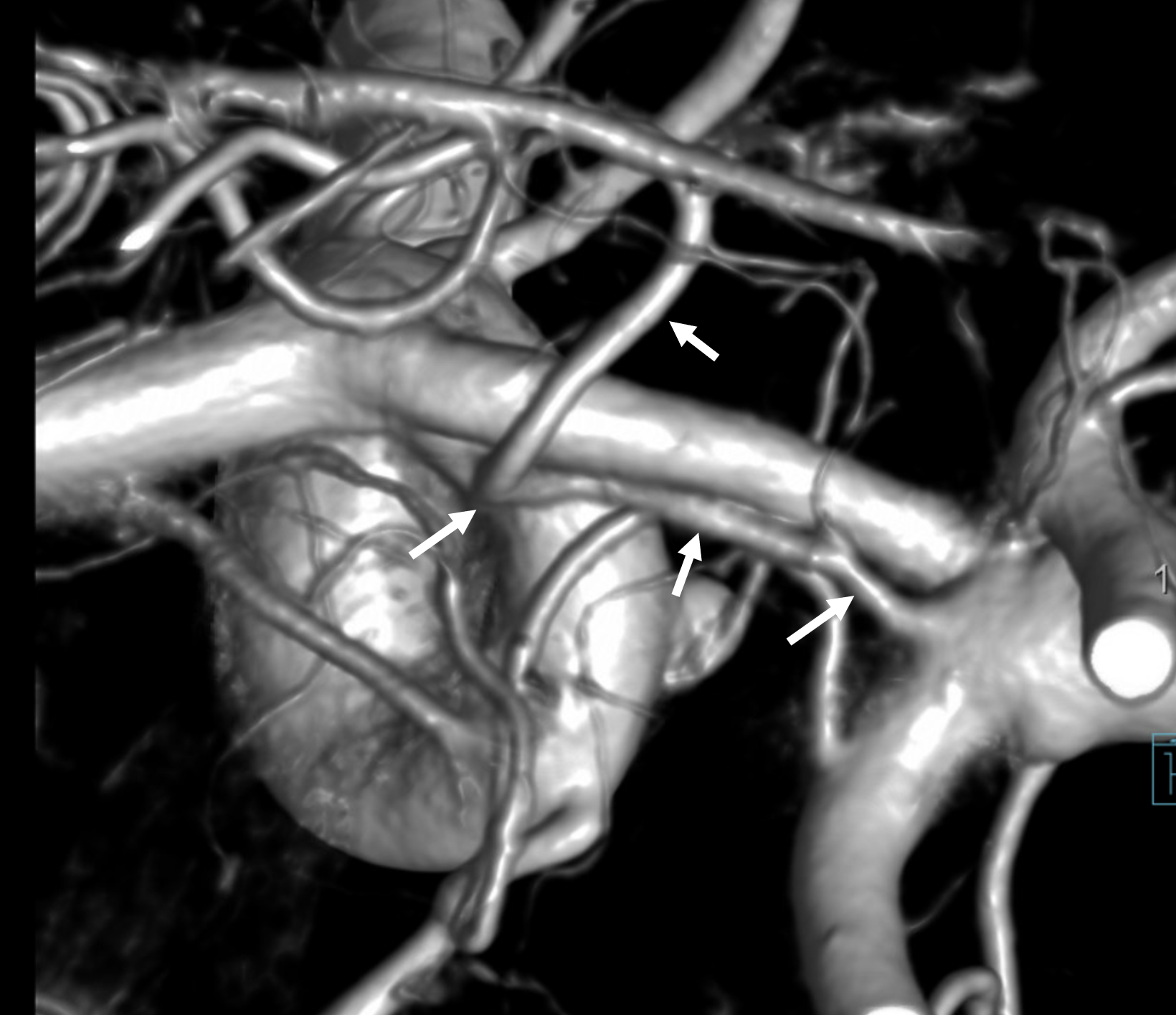
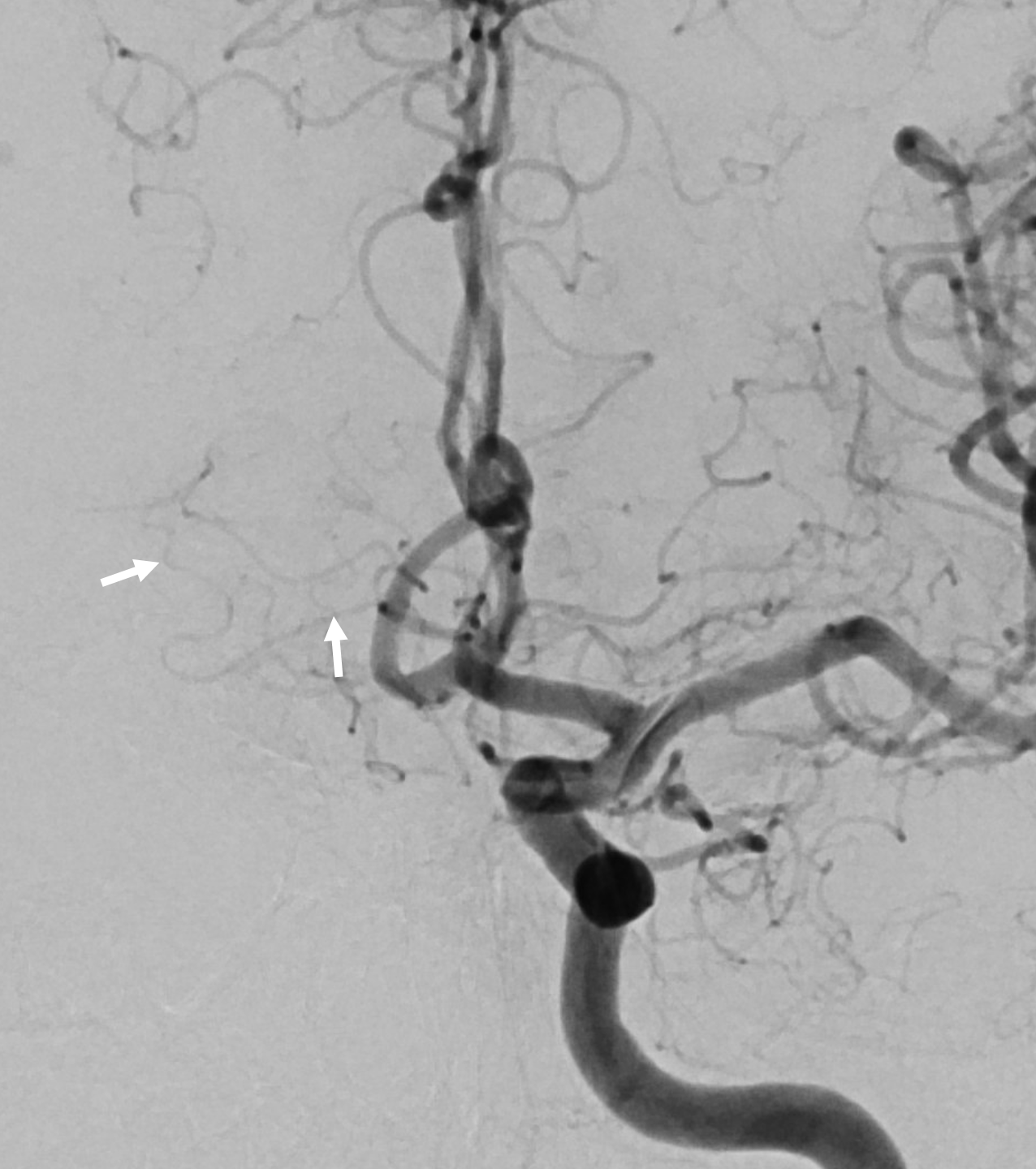
Here is a beautiful stereo image of RAH. It is often easier to see the Heubner angiographically from a contralateral injection where it is not obscured by other neighboring branches. Here, a prominent right RAH (blue arrows) arising from the A1-A2 junction is best seen from left ICA injection. The left RAH is marked by white arrows. Notice also an old carotid dissection
Same patient, DSA stereo. The spasm is due to a ruptured, coiled choroidal aneurysm. The dissection predates everything.
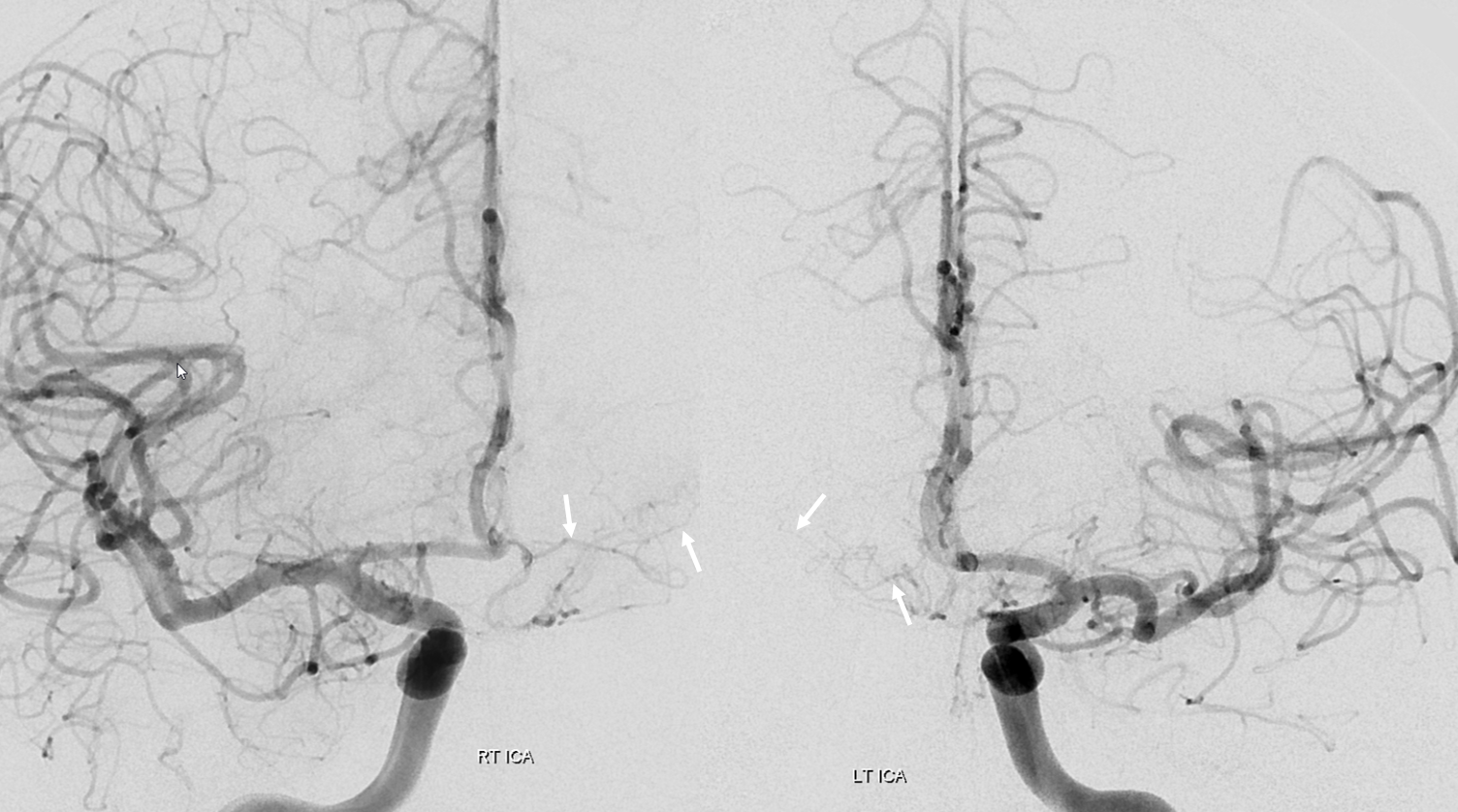
Below is example of Heubner being way better seen from contralateral injections on both sides of same patient
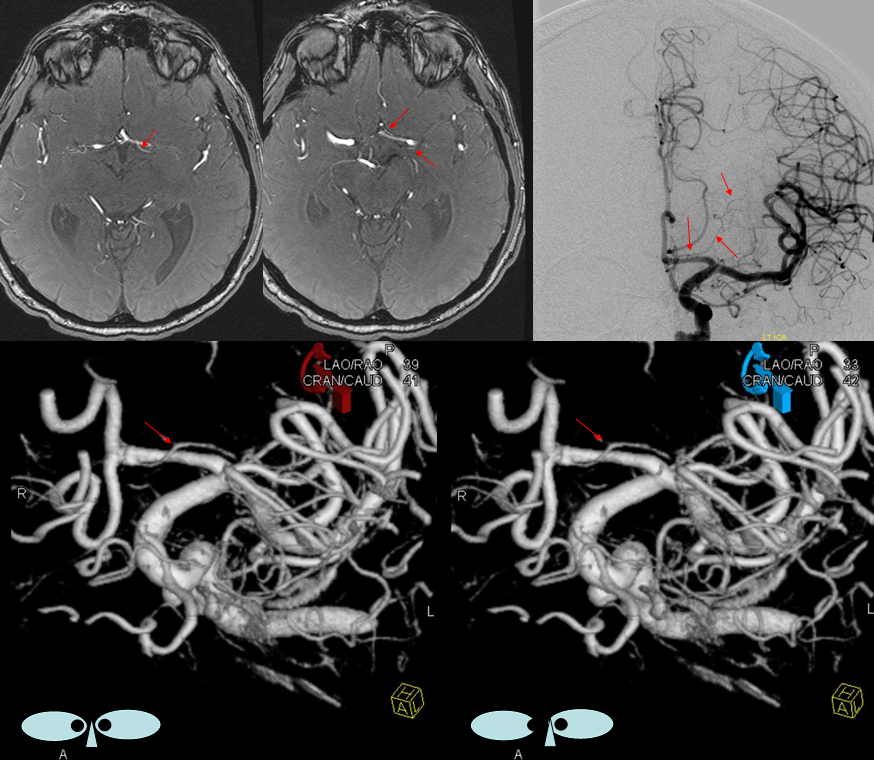
Another example of RAH. MRA, catheter angiogram, and 3-D DSA stereo pair demonstrating the same artery of Heubner.
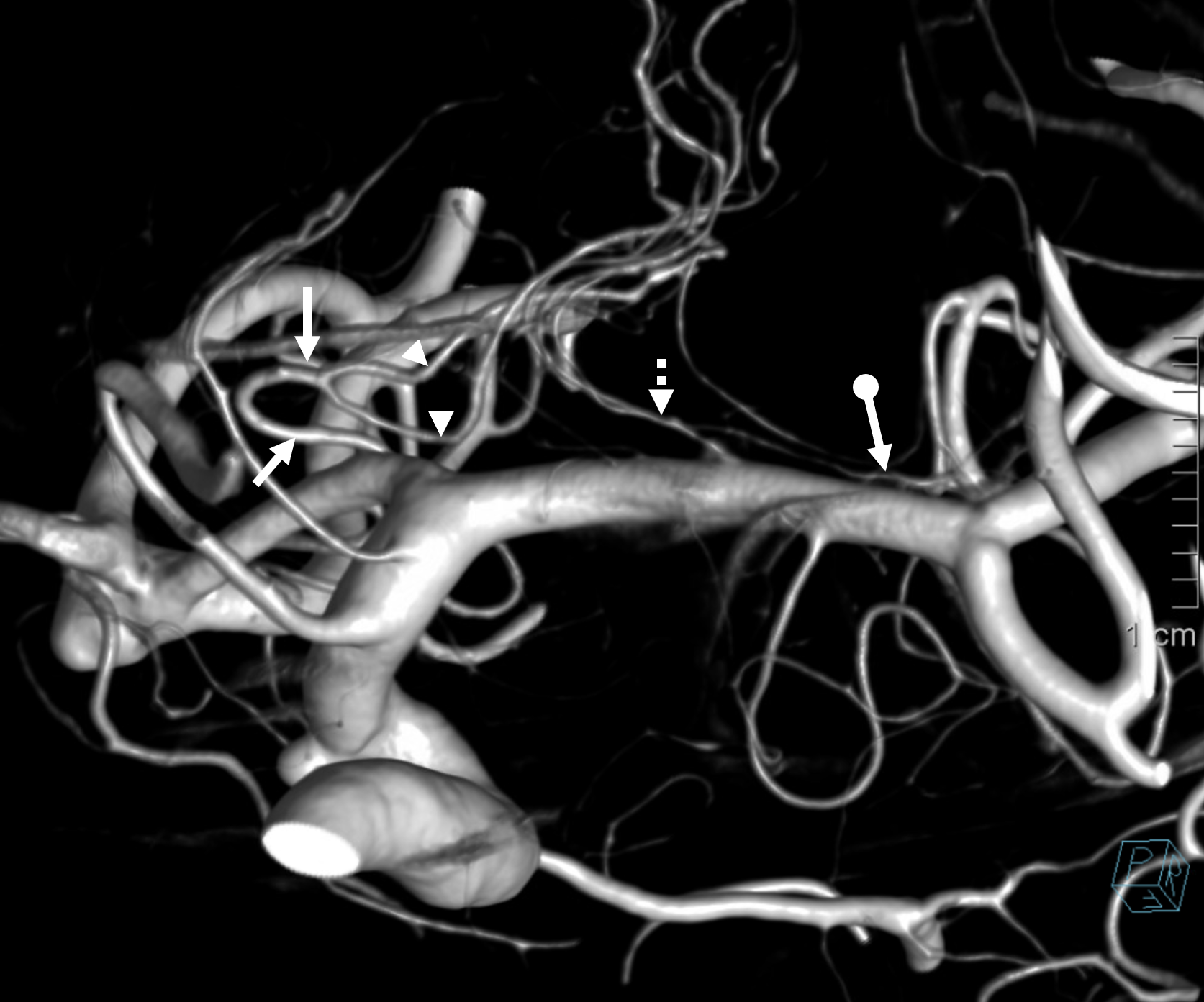
Here is a beautiful example of large RAH (arrow), extending into medial lenticulostriate territory and some lateral lenticulostriates (dashed arrow) too which are correspondingly small. A small cortical branch with separate origin (open arrow) passes for anther Heubner in some people’s opinion
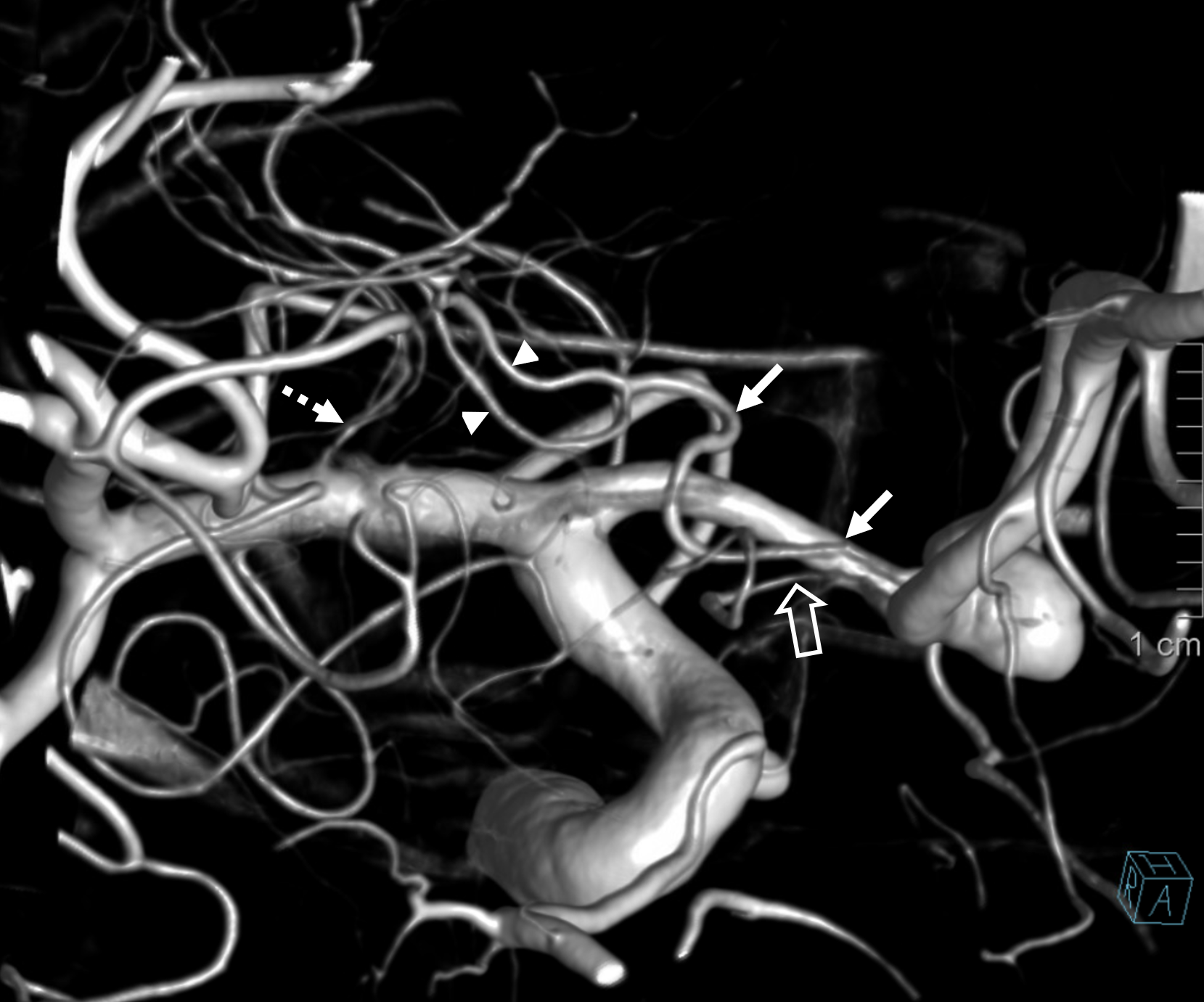
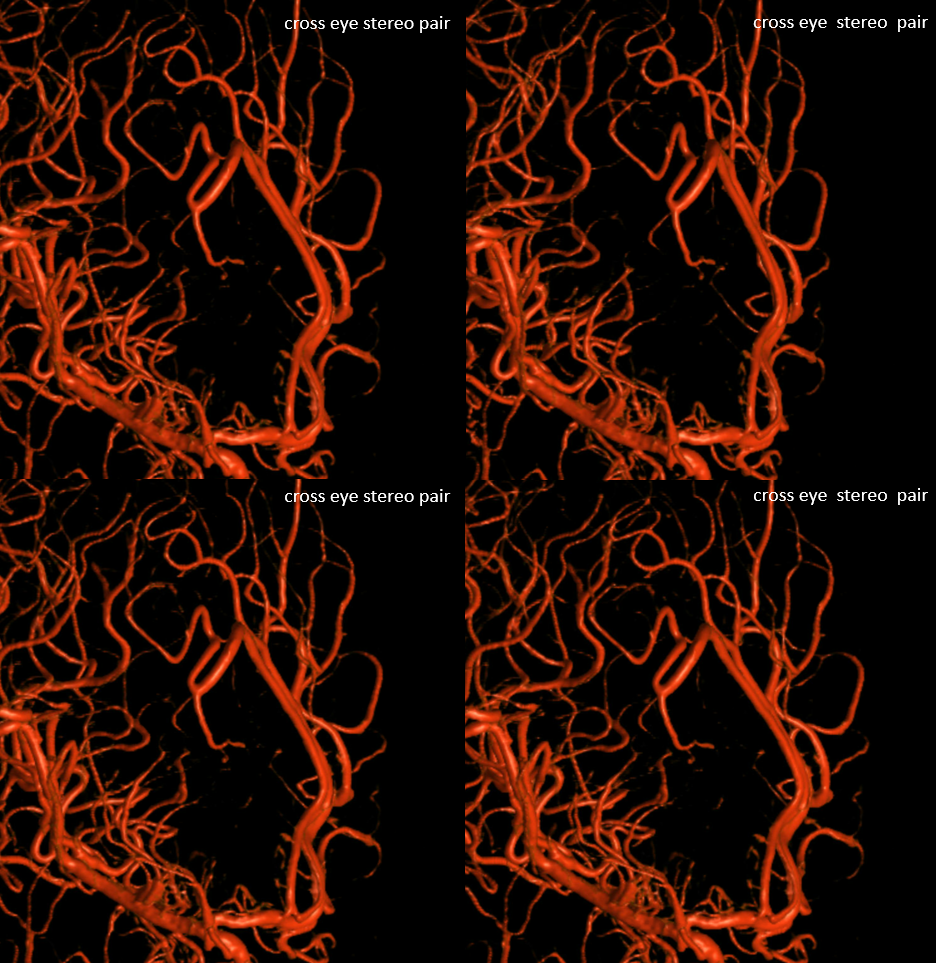
Cross eye stereo
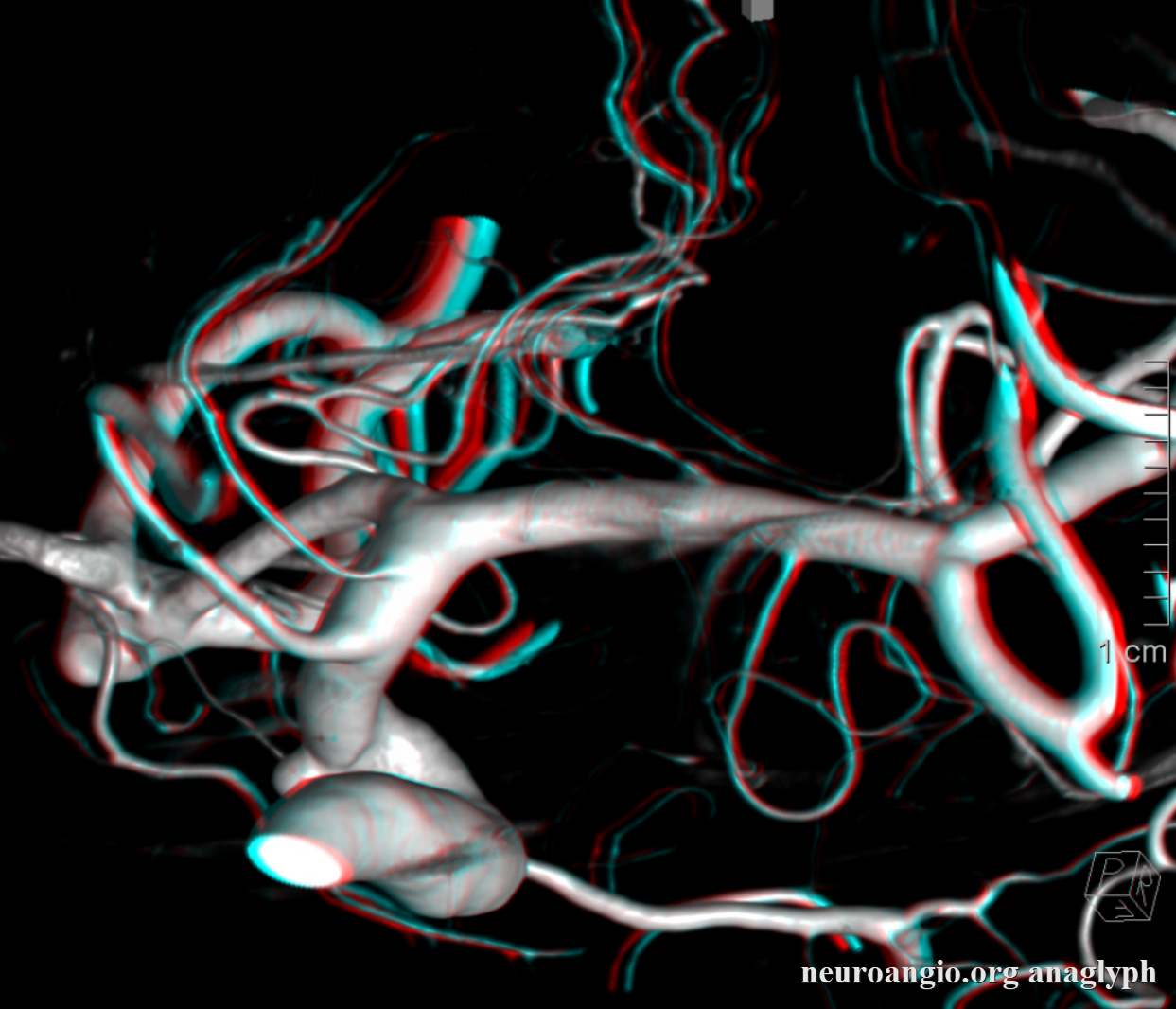
Anaglyph

View from back shows small caliber of lateral lenticulostriates (dashed arrows) — again balance — big Heubner means small lateral group. A very small and very lateral branch (ball arrow) is probably taking care of external capsule area
Anaglyph view from back
View from above shows its A1-A2 junction origin
Below is another super DYNA CT example, courtesy Dr. Erez Nossek. The large Heubner comes with a rare kind of fenestration (arrows). Heubner prominence is due to its extensive supply of lateral lenticulostriate territory (arrowheads). Its medial lenticulostriate territory supply (ball arrows) is in balance with a medial lenticulostriate perforator from the more proximal A1 (dashed arrow). Its lateral lenticulostriate territory is in balance with the “classic” group of lateral lenticulostriate arteries from the MCA (open arrows). Rhoton would have called the Heubner group “medial lateral lenticulostriates” and MCA ones “lateral lateral group”
Another example — global analysis
Top images are cross-eye stereos. Most of lateral lenticulostriate supply is from proximal M1 (white arrows). There is a smaller distal M1 lateral lenticulostriate also (dashed white arrows). On the ACA side, there is a large Huebner supplying medial lenticulostriate territory (dashed yellow), with a small lenticulostriate from proximal A1 also (solid yellow). Again, there is no “book” here — its a spectrum, with many possibilities to be individually visualized.
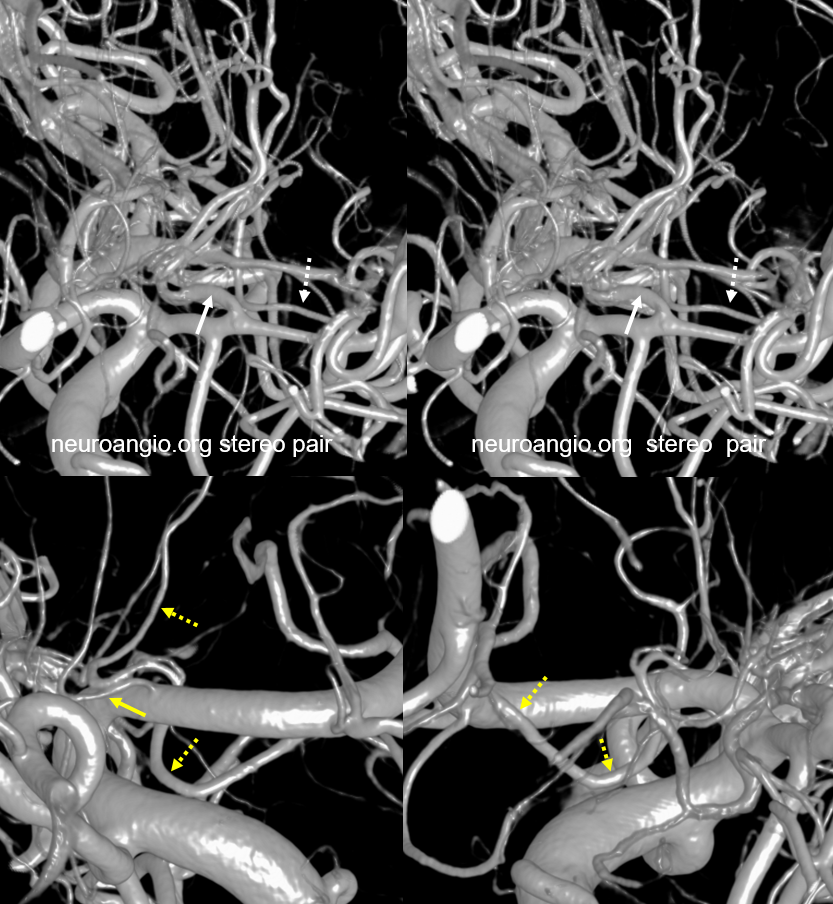
In this patient with a bilobed ACOM aneurysm, right (arrow) and left (dashed) arrow Huebner vessels are seen due to dominant right A1
An elegant way to see Heubner territory is by looking at DYNA CT cross-sectional images of a contralateral ICA injection. Here territory is shown in ovals
DYNA VR images. The ipsilateral Heubner (also proximal A2 origin) is dashed arrows
An elegant, if inconstant, way to see Heubner territory is by looking at CBCT MIP images. In this case, the territory is well seen (ovals)
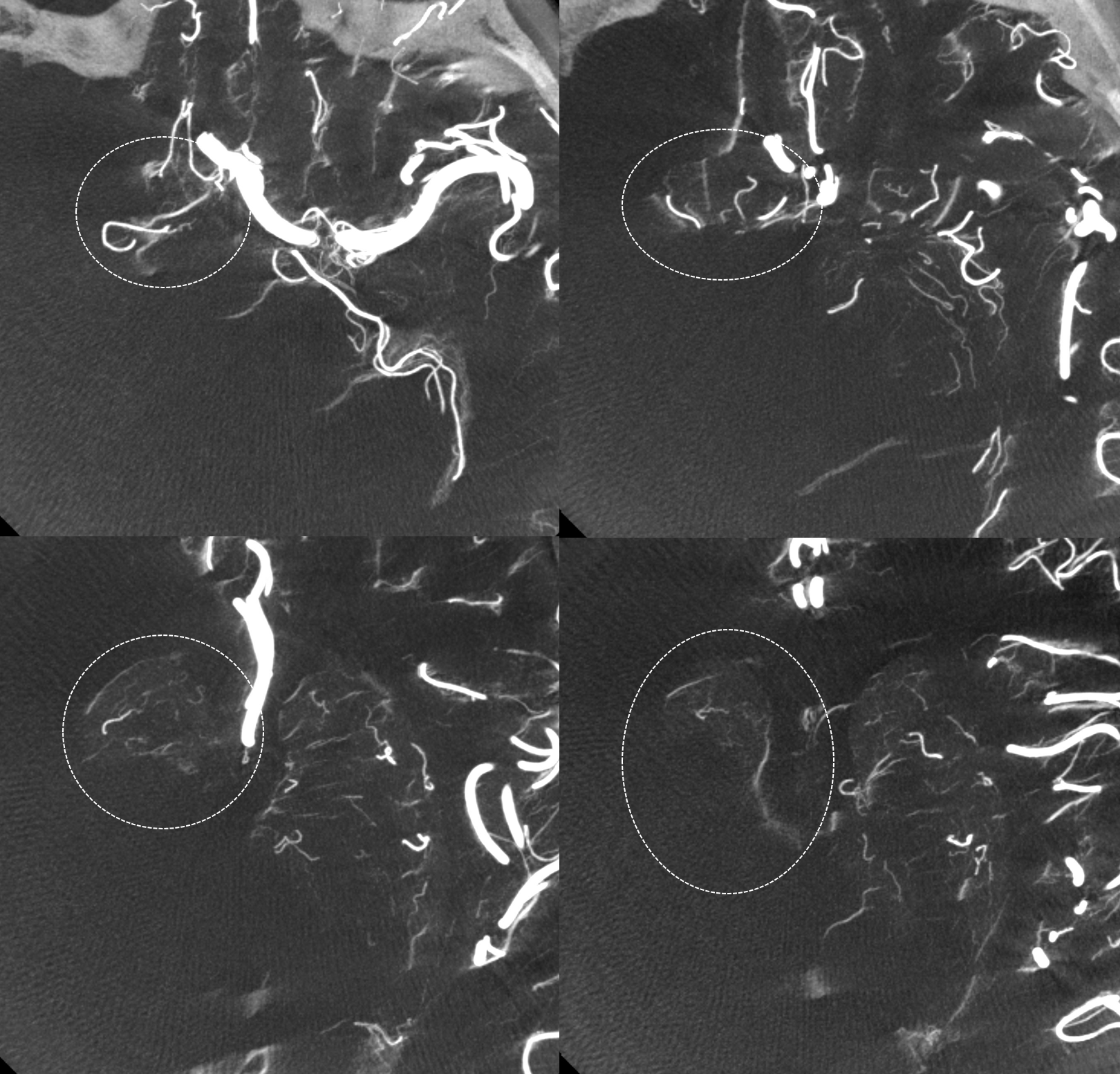
Not bad huh — remember “balance”
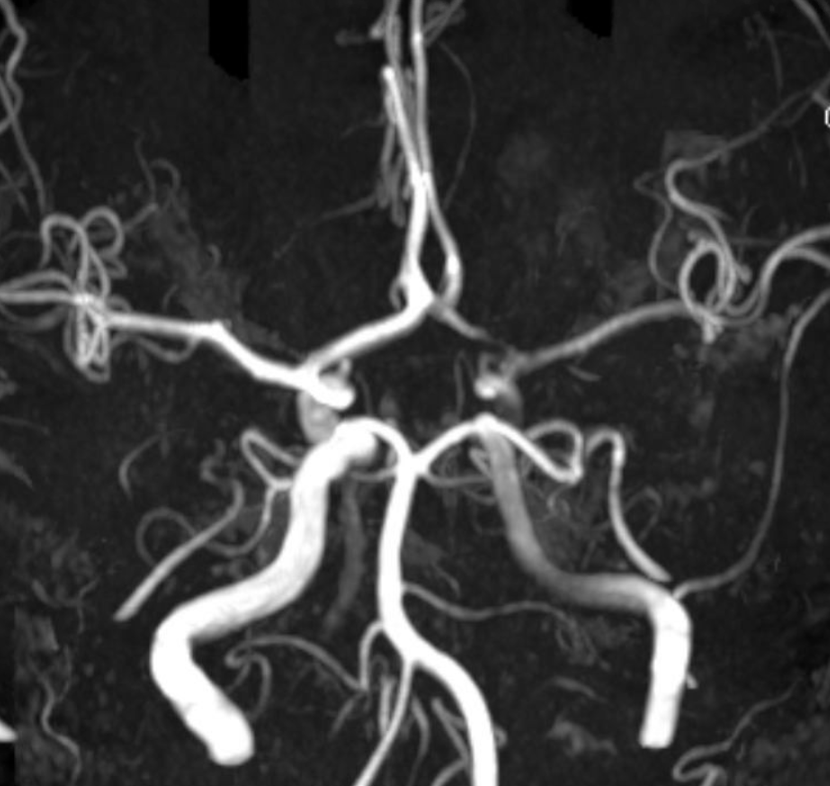
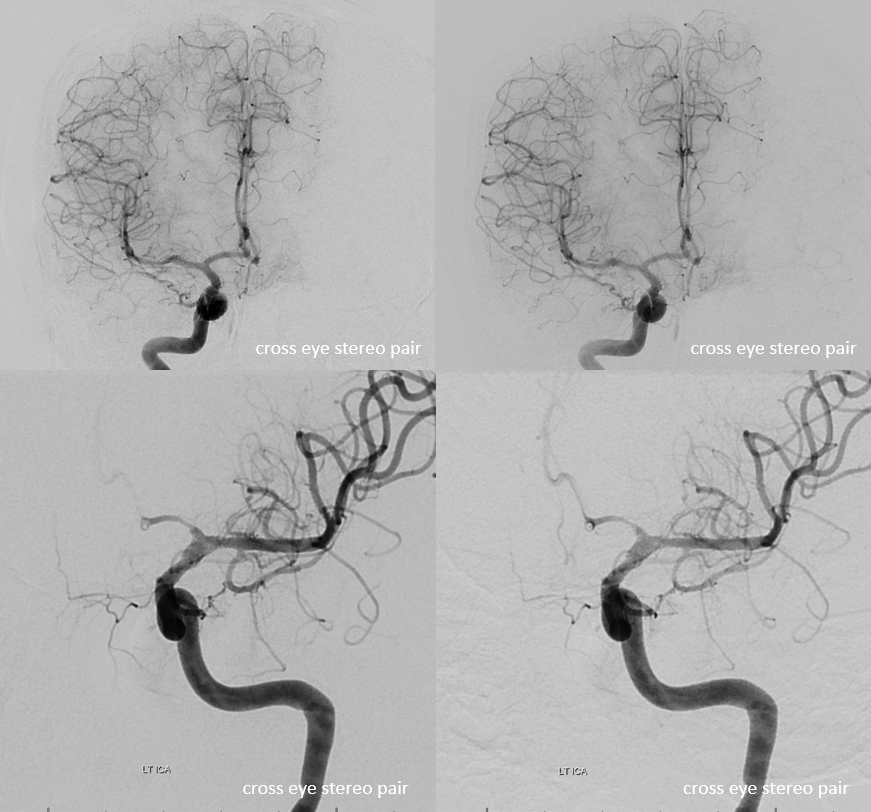
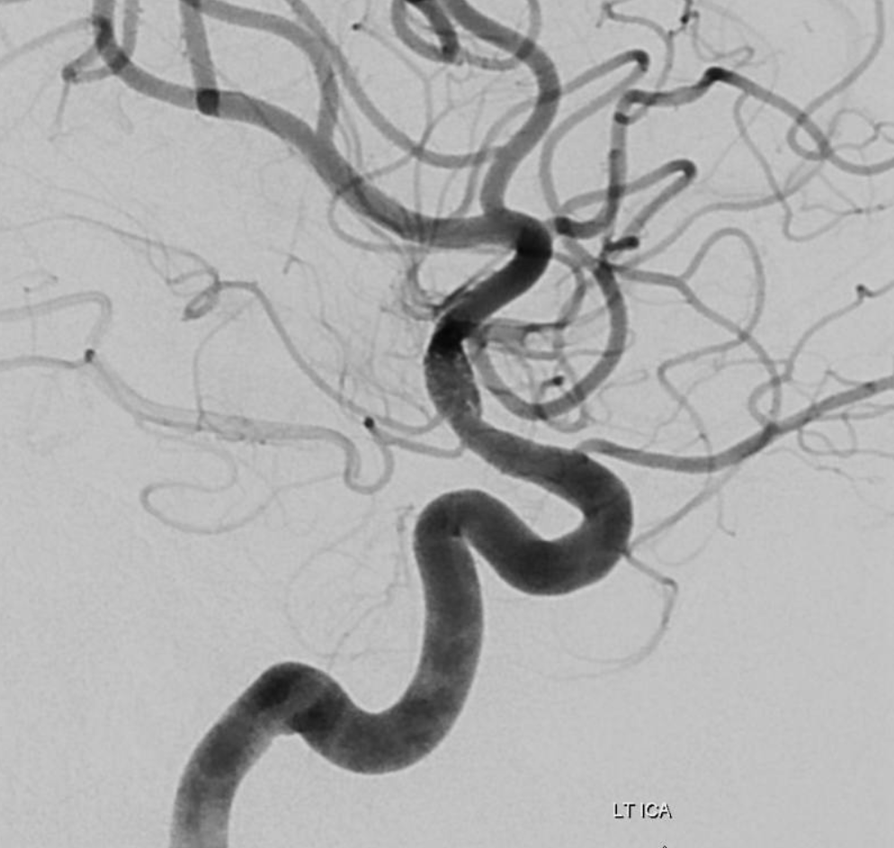
Heubner territory Infarct
As we emphasize throughout the site, there is a spectrum of variation in Heubner territory, like in anything else. Defining the exact territory Heubner supplies or the number of its branches is silly. There may be 1 or 2 heubner-like vessels, just like there may be grouped or separate origin lateral lenticulostriates. The general territory is well known. Here is an example of an infarct in a patient with A1 segment disease — this is the classic heubner infarct
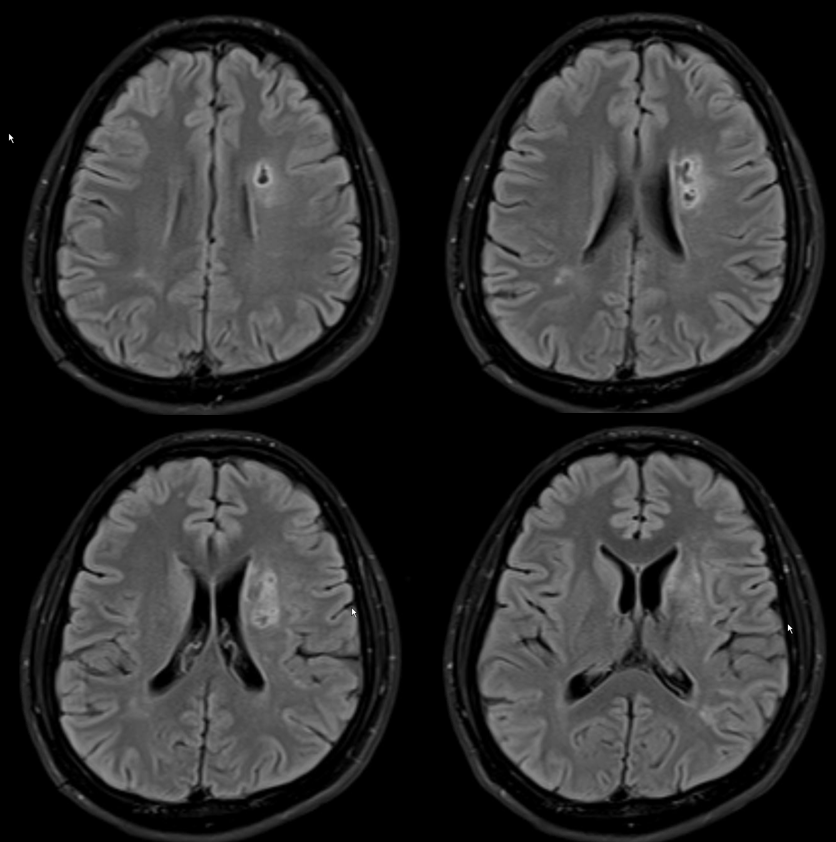
MRA
Angio stereos — notice no evidence of Heubner vessel from right ICA injection
Disease extends into the supraclinoid ICA
Heubner and M1 perforators
Again, 3-T MRA is very nice for small arteries like Heubner. This is a very clear demonstration that Heubner and medial perforators off the MCA serve the same function. In this patient, a large Heubner on the left serves the same function as the medial M1 perforators on the right, supplying the putamen, caudate, and parts of the anterior limb of the internal capsule.
Red=Heubner; Yellow=lateral perforators
Right MCA, same patient
Yellow=lateral perforators; Red=medial perforators
Heubner in patient with no MCA — the anterior choroidal artery and Heubner artery are well seen in this patient, whose MCA was surgically removed in context of a left hemispherectomy for intractable seizures. The anterior choroidal, which appears duplicated, captures some of the posterior temporal/occipital territory. The heubner and its basal ganglia parenchymal blush are well seen.
Red = Heubner; Orange = Anterior Choroidal; Purple = PCA; Blue = distal superior cerebellar artery visualized through reflux into the basilar.
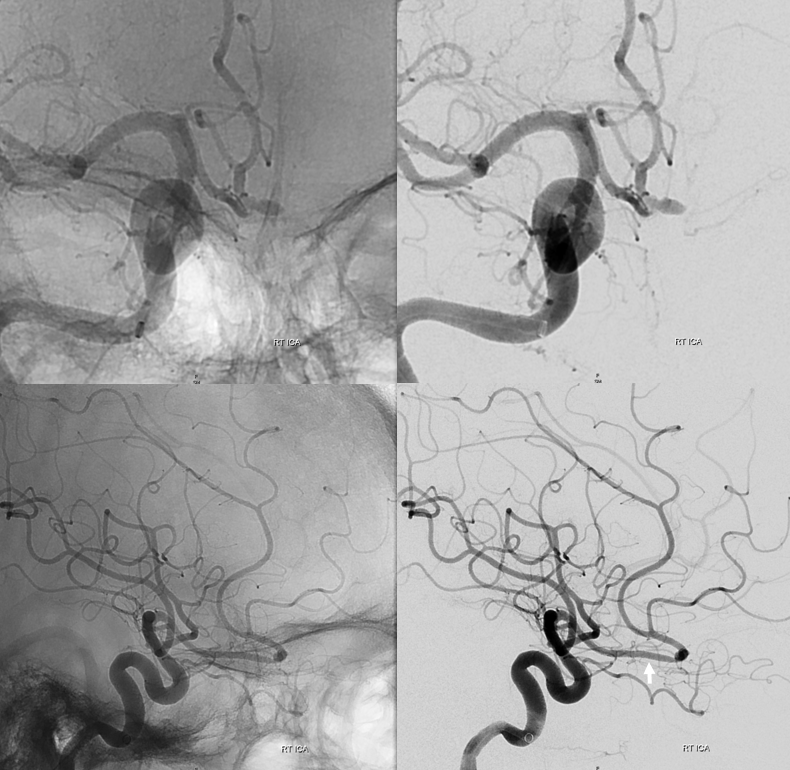
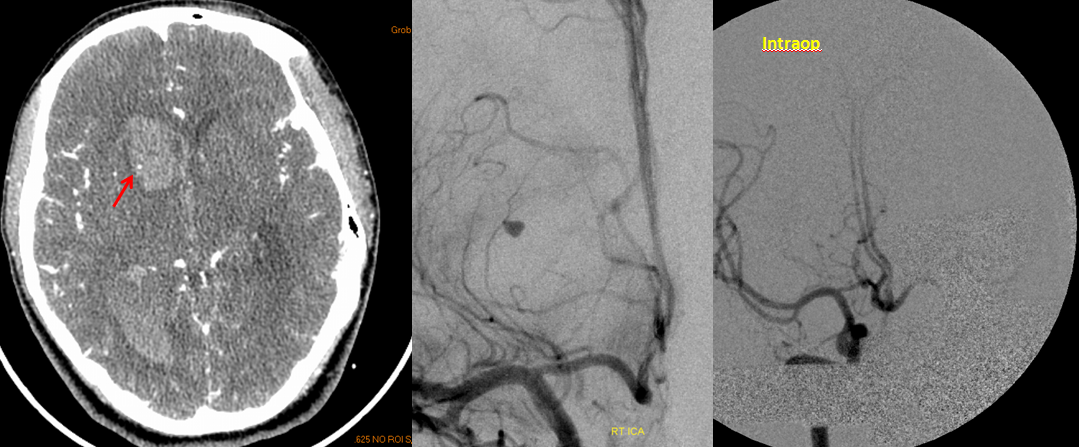
RAH pseudoaneurysm — a case of parenchymal hemorrhage from a RAH. The CTA demonstrates a “spot sign” (red) which, within a hematoma, is strongly suggestive of source of bleeding (active or pseudoaneurysm). No delayed images were acquired, unfortunately. Angio (middle) demonstrates the aneurysm. Intraoperative angiogram (right) following aneurysm surgery.
Stereo pairs of same case 1 week (top) and two weeks (bottom) following hemorrhage, demonstrating interval aneurysm growth — in fact showing an enlarging pseudoaneurysm in face of resolving hemorrhage. The patient was operated on after the second angiogram.
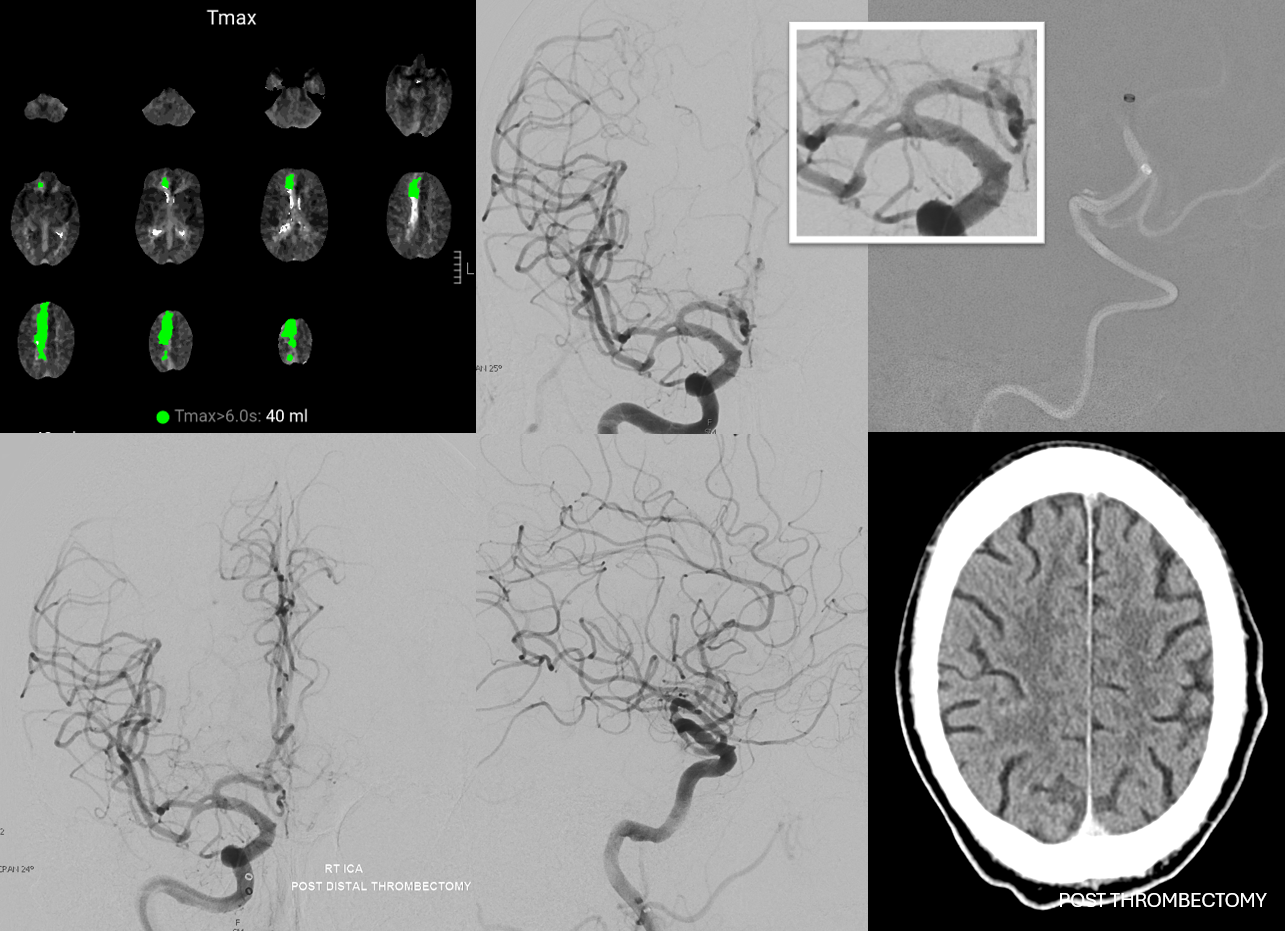
ACA Embolus — MCA fenestration
Who says MCA fenestrations are without clinical significance? In the case below, embolus favors ACA as a result of MCA fenestration. Long live distal thrombectomy!!!
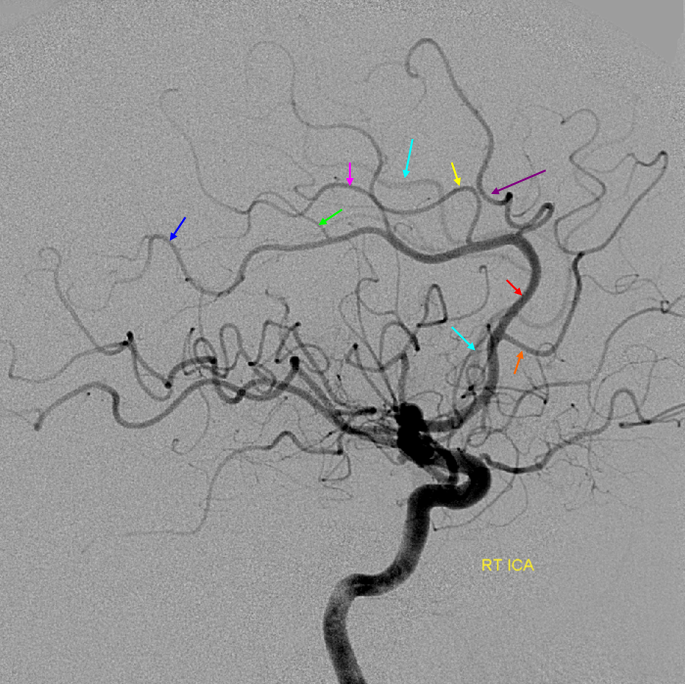
Cortical branches and variations
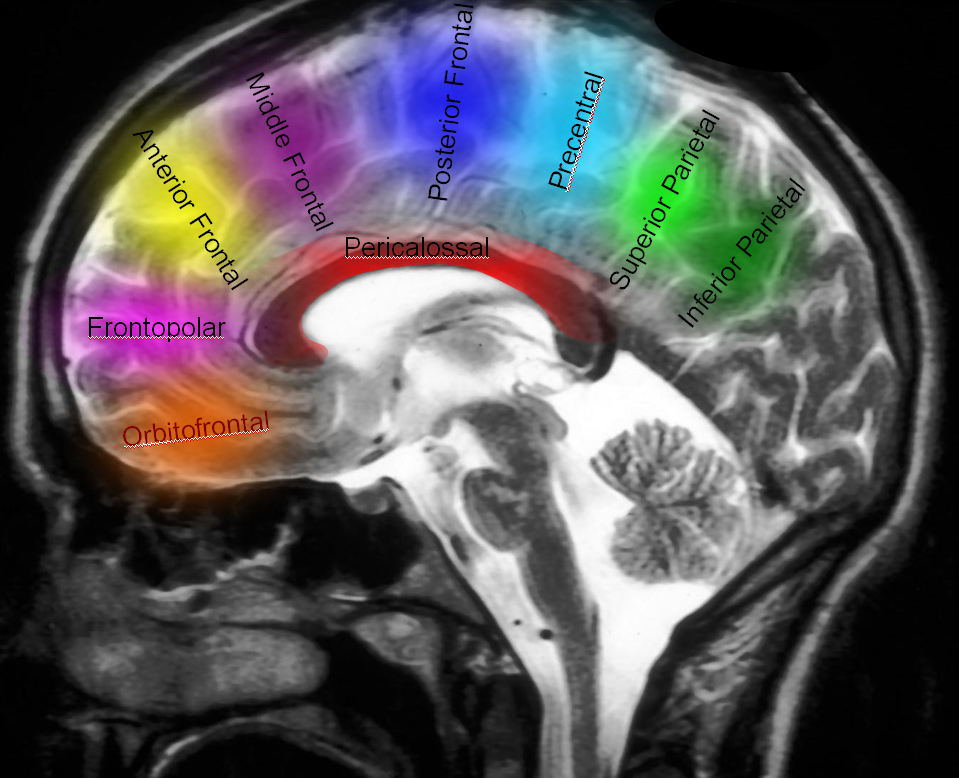
Naming scheme for cortical ACA branches — no educational endeavor is complete without a silly diagram like this. Extreme variability is the rule. As long as there is understanding of where the artery is going to, naming is a matter of semantics. Naming classifications are variable, this one is as reasonable as any other.
Examples of variability are given below.
No callosomarginal artery — medial hemispheric branches originating from a dominant pericallosal
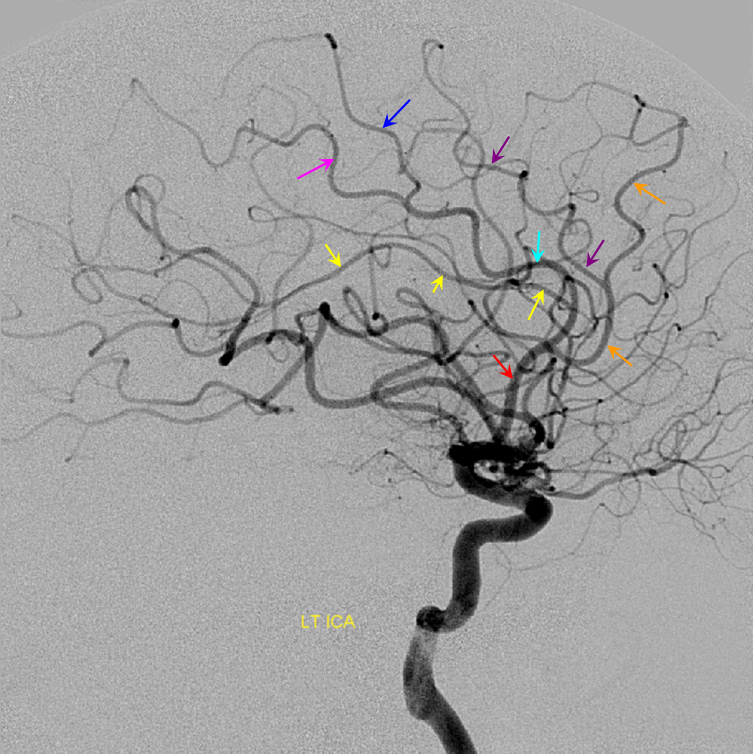
Dominant Callosomarginal Artery — same patient as with no callosomarginal, contralateral side
Dominant Callosomarginal Artery — another example of variability in the pericallosal-callosomarginal balance.
“Trifurcation” of post-genu segment; (plus superior hypophyseal artery)
Early callosomarginal takeoff at ACOM level (same case as above “triplicated aca”)
Subcallosal / Median Callosal Arteries
Another supposed variant but not really. Again, its all about the pericallosal/callosomarginal balance. The subcallosal artery is a name given to a branch that typically takes off near the ACOM and swings slightly back and up along the anterior margin of the hypothalamus and underneath the corpus callosum (hence “subcallosal”). Its importance is that it supplies the hypothalamus. If inadvertently clipped or coil-occluded during aneurysm treatment, clinical consequences are devastating. The same branch can continue as supply to the corpus callosum and cingulate especially when there is a dominant callosomarginal system. If so, it is called the “median callosal artery” — basically the same thing as a pericallosal but without cortical branches. Picture below shows this “subcallosal-median callosal artery. The more proximal subcallosal is dashed white arrows, distal “median callosal” is solid white. On the left, there is a more dominant callosomarginal system (yellow arrows) whereas on right there is a more balanced pericallosal (red) and callosomarginal (purple) trunks.

without labels
Stereo cross-eye
Anaglyph stereo

A less deep anaglyph
Angios — much harder to figure out than VRs
Another example — median callosal ACOM origin DYNA VR
Distal Pericallosal redundancy — limbic arch?
A curious redundancy of the distal pericallosal artery — a somewhat strange appearance on DSA (arrows)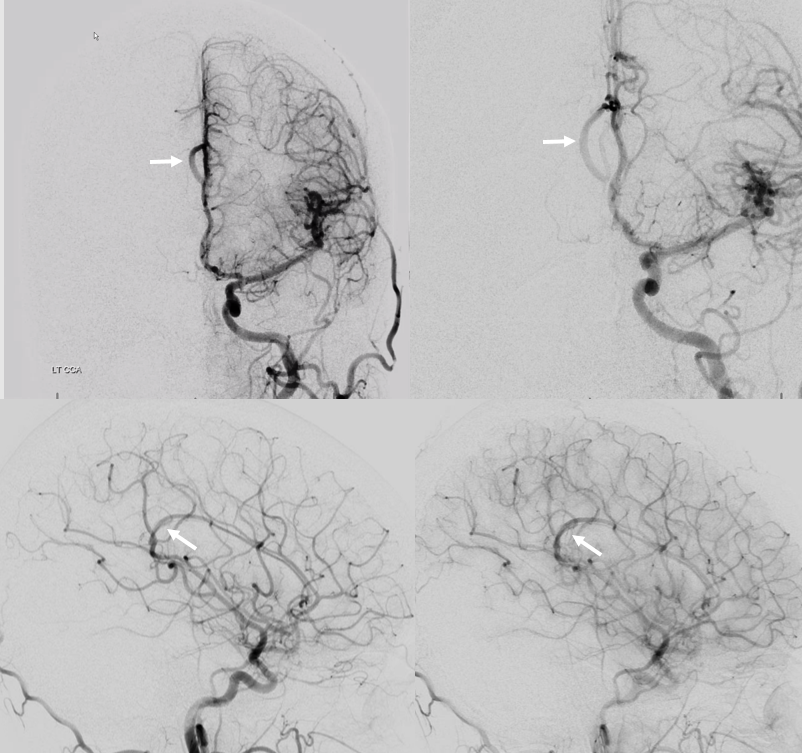
Stereo volume rendered images — a recurved distal pericallosal configuration which might be on the spectrum of Lasjaunias (and others) discussion of limbic arch. Of no clinical significance
Bilateral mesial hemispheric supply — biparietal / bifrontal trunk
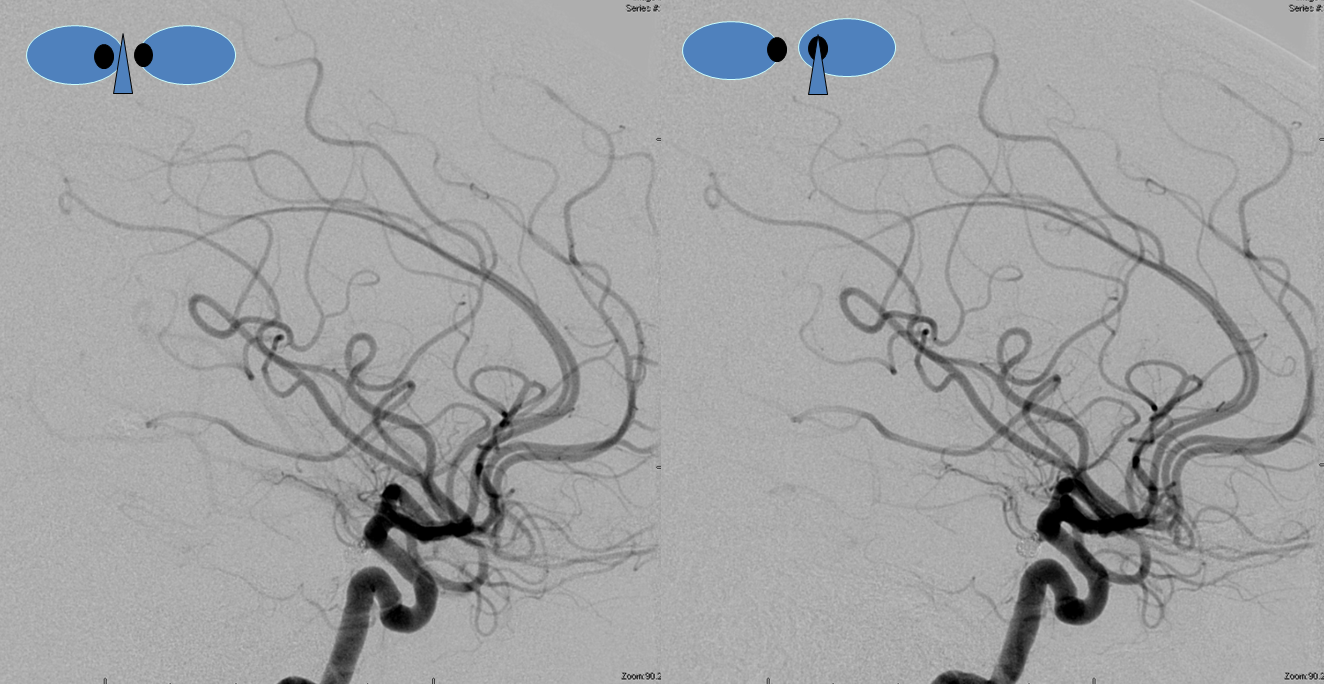
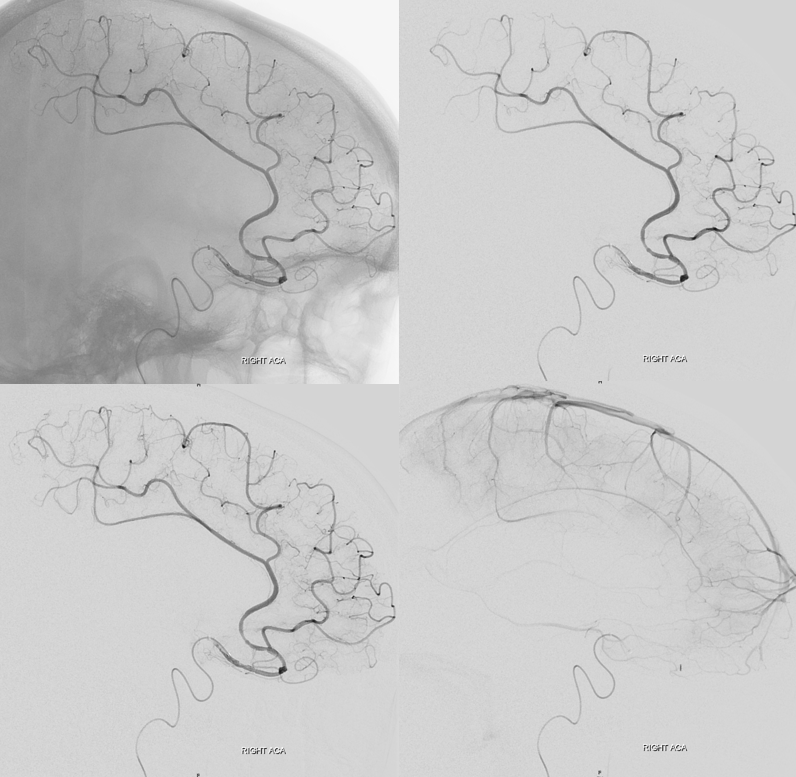
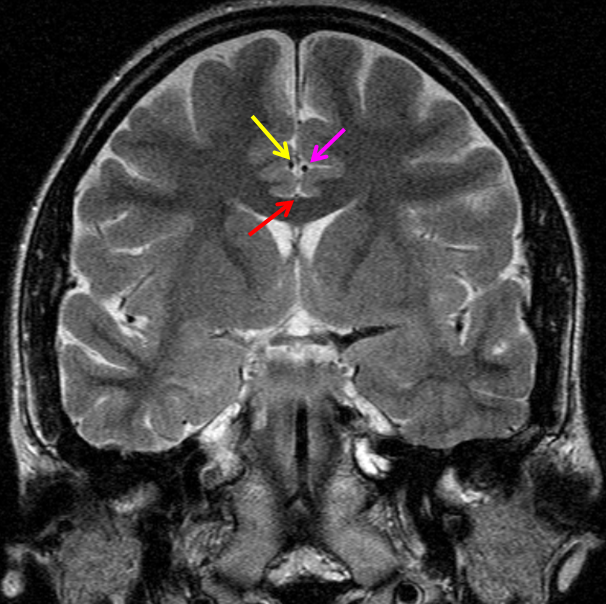
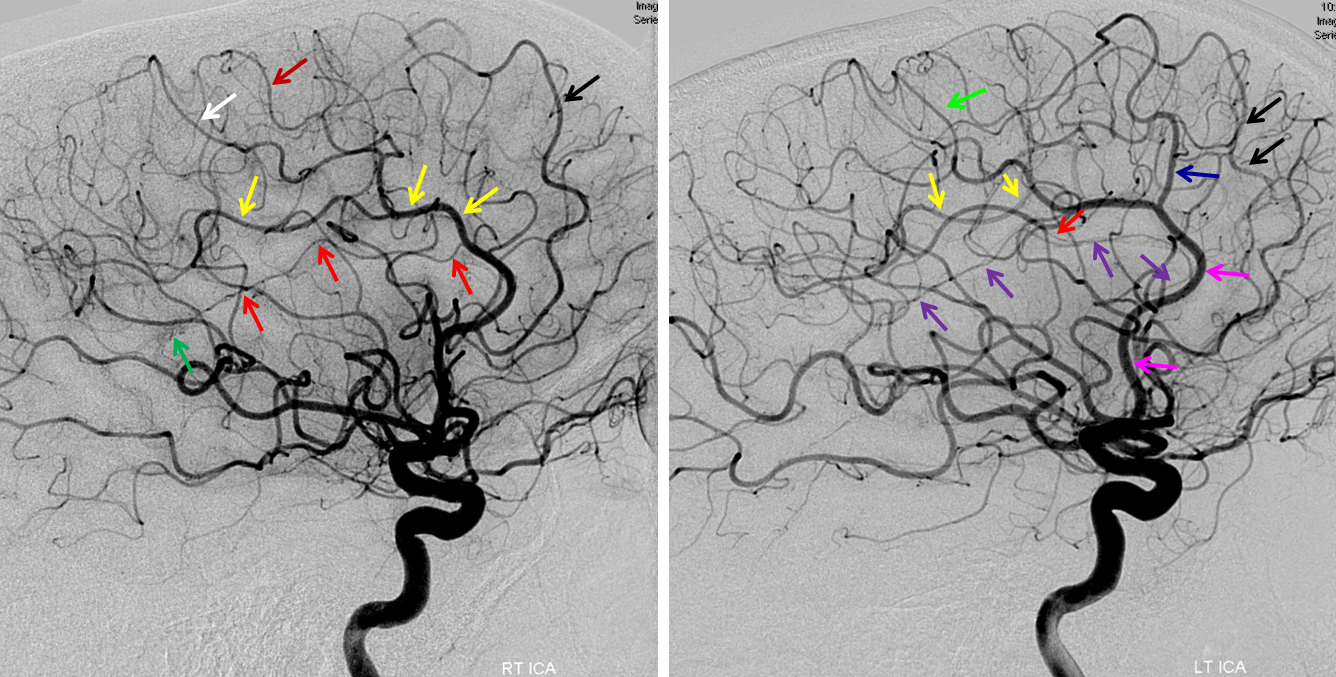
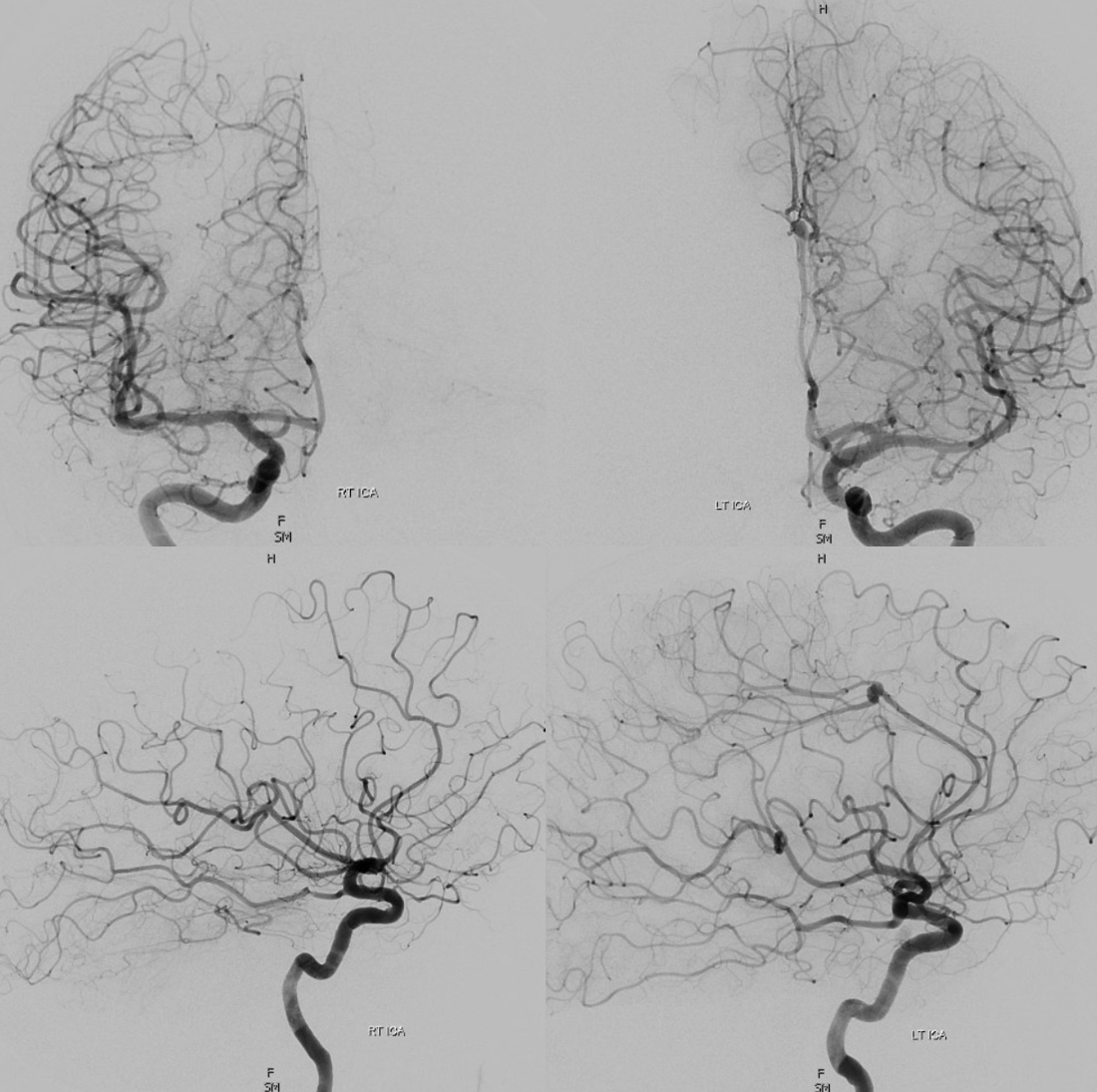
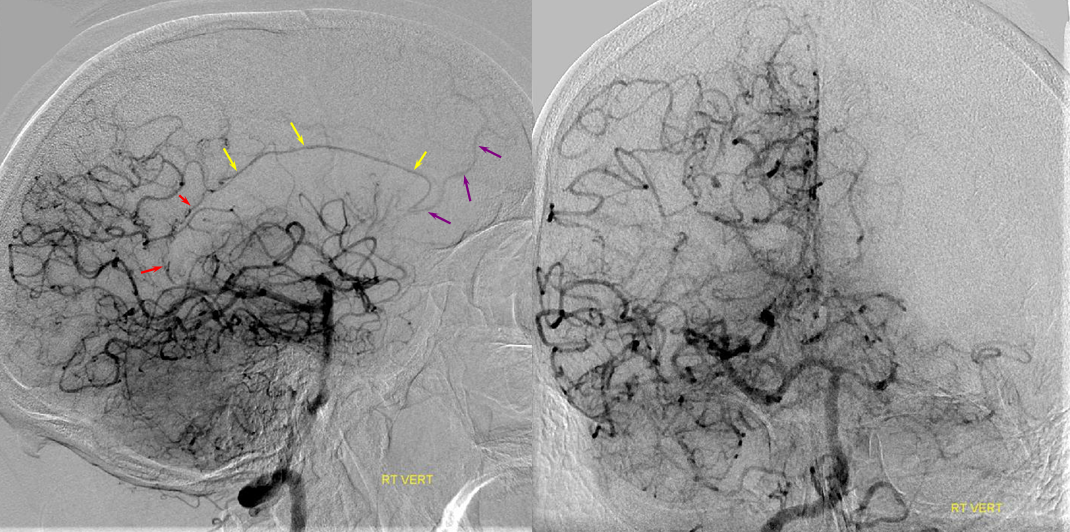
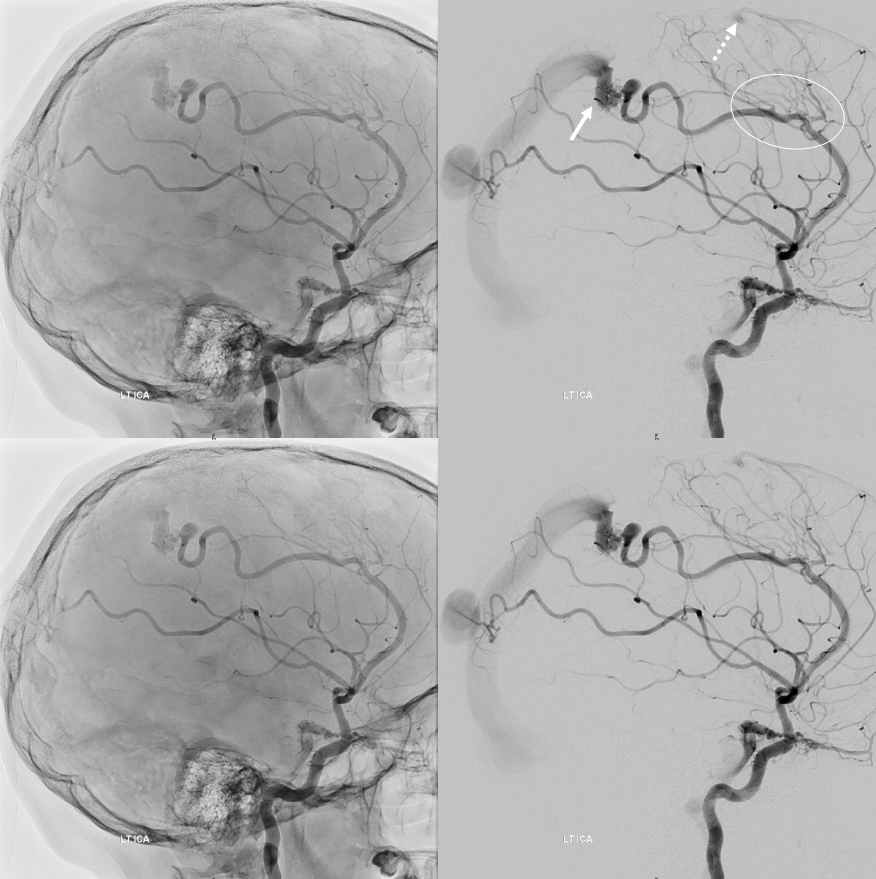
A clinically important variant — the ideas or spectrum and balance in supply — anything is possible — dominant pericallosal, callosomarginal etc. In these particular cases, the A2 is not azygous. however, the distal ACA territory of both sides is supplied by either left or right system. See below — on the right, the A2 territory is basically limited to callosomarginal — mesial anterior and mid-frontal areas (best seen in right ICA lateral injection). On the right, the dominant pericallosal supplies both mesial posterior frontal and parietal lobes (left ICA frontal view).
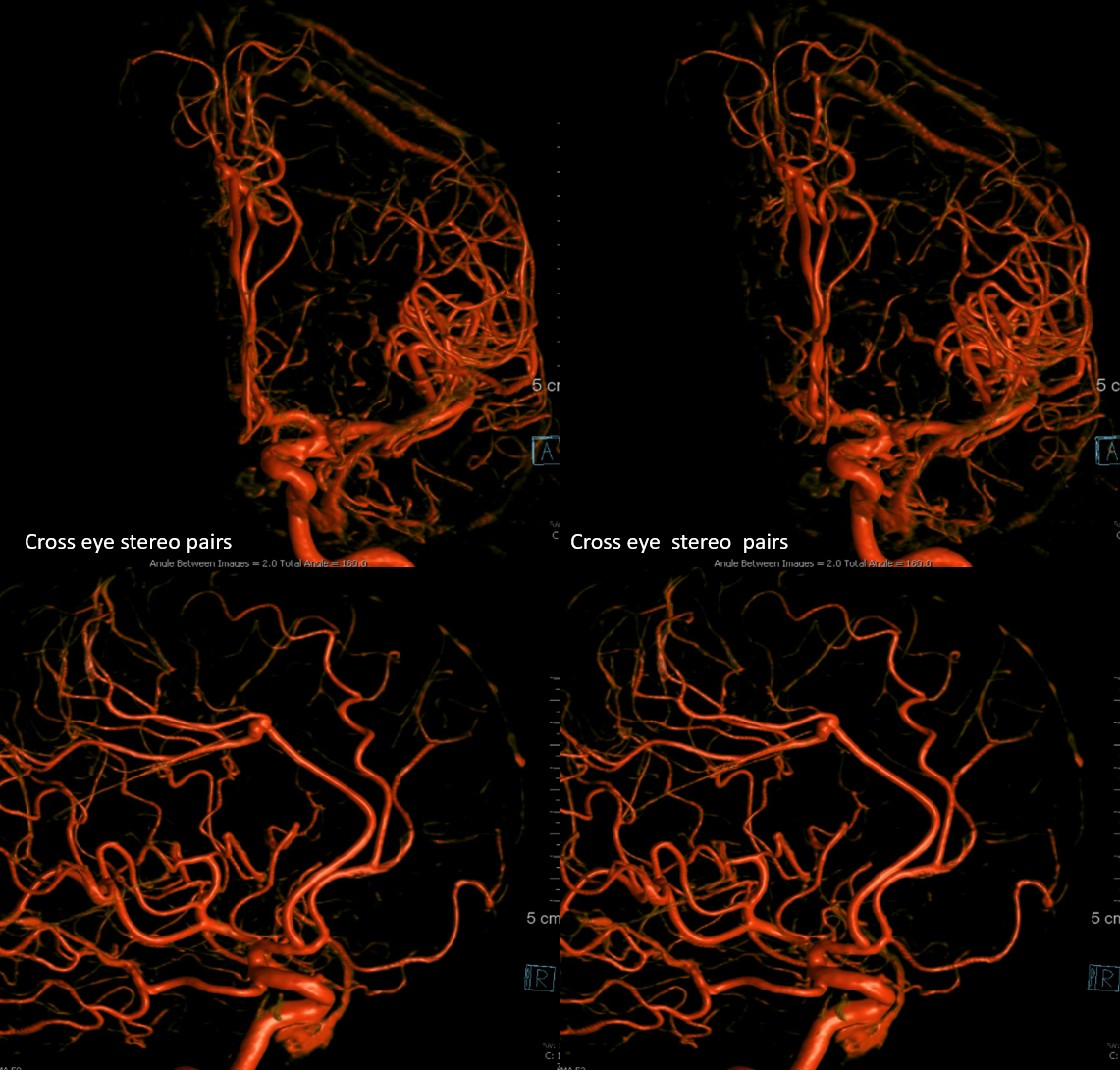
VR stereos
This leads to the clinically important situation of dominant pericallosal artery occlusion resulting in bilateral lower extremity weakness — mimicking a spinal issue.
ACA territory collateral circulation
PCA (particularly posterior pericallosal / splenial branches can effectively reconstitute distal pericallosal ACA territory. Embryologically this corresponds to a PCA/ACA anastomosis which exists in some mammals and possibly in the human embryonic stage.
Carotid Occlusion — PCA reconstitution of the ACA territory.
The right ICA is occluded at the origin. Notice how effectively posterior pericallosal branches of the PCA (red) can reconstitute the pericallosal territory of the ACA (yellow), with runoff into the anterior frontal branch (purple)
Balance anterior – posterior pericallosal
Another example of anterior-posterior pericallosal balance. The A2 is unpaired. Small “distal pericallosal” aneurysm is seen on the right. The very “distal” median callosal artery is small (arrows). A correspondingly large posterior pericallosal (dashed white arrows) is noted — balance again. There is also balance in choroidals. The anterior choroidal contribution to lateral ventricle choroid supply is small (white arrowheads). The corresponding dominance of posterior lateral choroidal (yellow dashed arrows) is present. Also seen is a large posterior medial choroidal (yellow arrowheads).
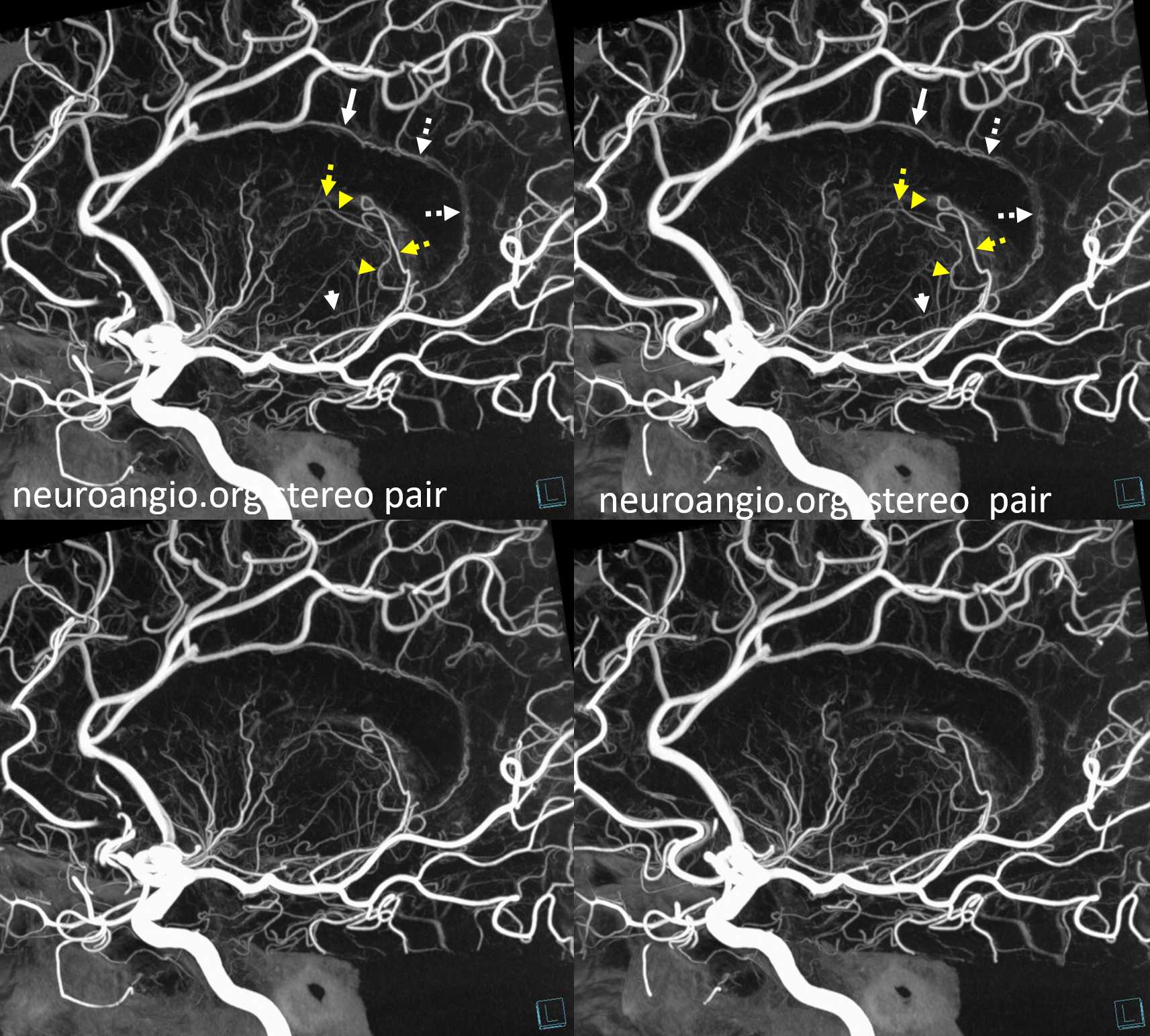
Anterior Cerebral Artery (distal pericallosal) origin posterior medial choroidal artery (arrows).
It happens… Check out this one as seen on DYNA CT — notice lack of posterior medial choroidal visualization off the vert injection — where a well-developed left posterior lateral choroidal (dashed arrows) is present. The point where posterior medial choroidal goes into the ventricle is just distal to the crosshairs — same epsilon sign. See more on Posterior Choroidal Artery page
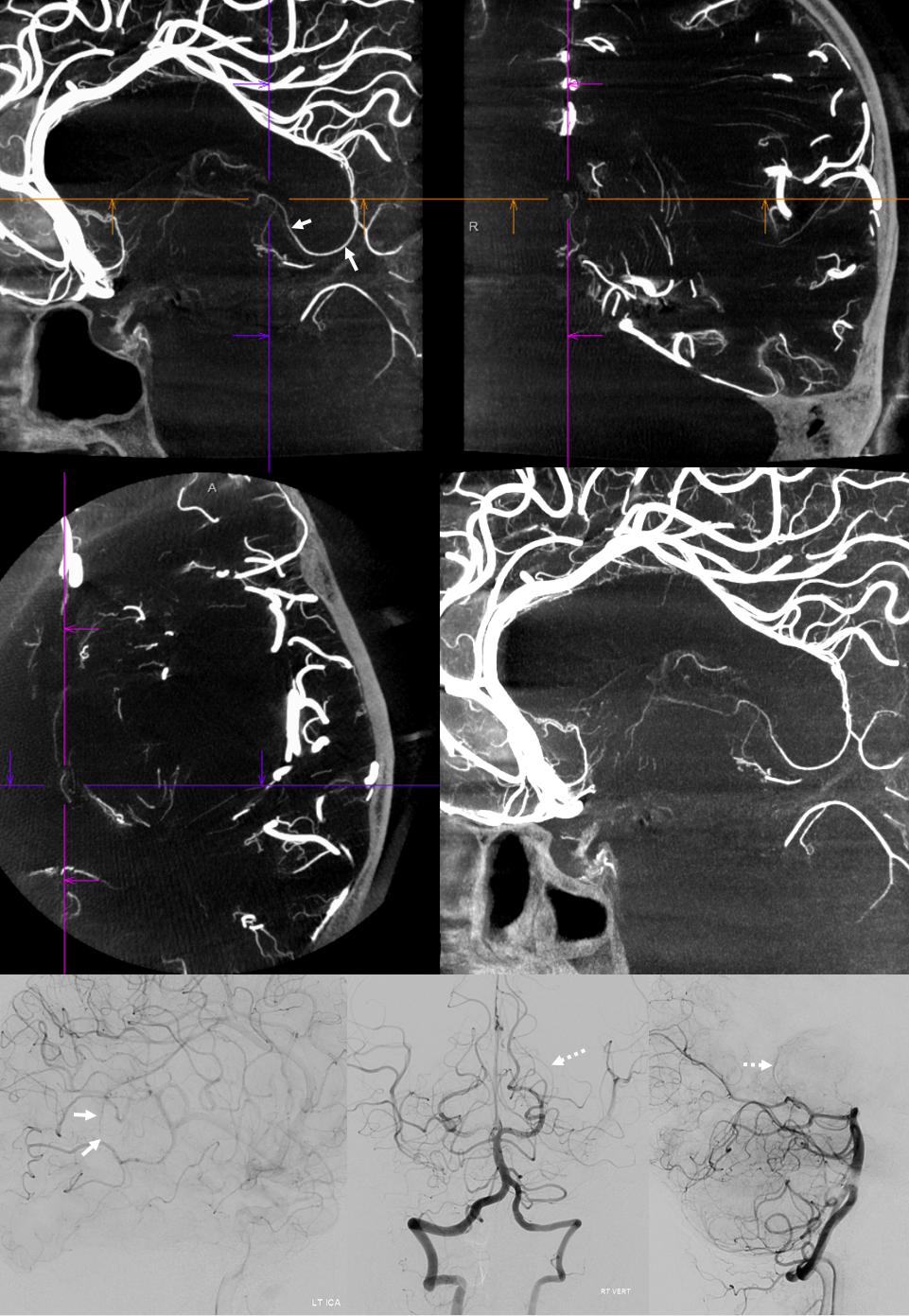
ACA Piodural Anastomoses
Very rarely seen in normal states. Not so rare with fistulas. Here is a patient with innumerable huge fistulas. There is some supply from ACA to the superior sagittal sinus ones. Two separate fistulas. The oval is over piodural supply to falx arterial channels. Fistulas are in the SSS
Pericallosal Vein
Every artery is married to its own, parallel-running vein. At least one. Lest you think this is not true, here is an ANAGLYPH venous phase of ACA injection in a patient with an A2 segment stenosis. There is a vein draining into the Galen confluence — the posterior pericallosal / pericallosal vein. Now you know